



Gemma 4とは何か
2026年4月2日、Google DeepMindは新世代のオープンモデルファミリー「Gemma 4」をリリースしました。Gemma 4は、同社のフロンティアモデル「Gemini 3」と同じ研究・技術基盤から構築されており、ローカルハードウェアで動作する「Gemini 3」とも言える位置づけです。
モデルは用途に応じて4種類に整理されています。大規模ワークロード向けには31B Dense モデルと 26B Mixture-of-Experts(MoE)モデルが提供され、どちらも最大256Kトークンというコンテキストウィンドウを持ちます。一方、エッジデバイス向けには Effective 2B(E2B)と Effective 4B(E4B)が用意されており、スマートフォンやRaspberry Pi、NVIDIA Jetson Orin Nano上でも完全オフライン・ほぼゼロレイテンシで動作します。
モデル | パラメータ | アーキテクチャ | コンテキスト | 音声入力 |
|---|---|---|---|---|
Gemma 4 31B | 31B(Dense) | 通常Dense | 256K tokens | 非対応 |
Gemma 4 26B | 26B(A4B MoE) | Mixture of Experts | 256K tokens | 非対応 |
Gemma 4 E4B | Effective 4B | エッジ最適化 | 128K tokens | 対応 |
Gemma 4 E2B | Effective 2B | エッジ最適化 | 128K tokens | 対応 |
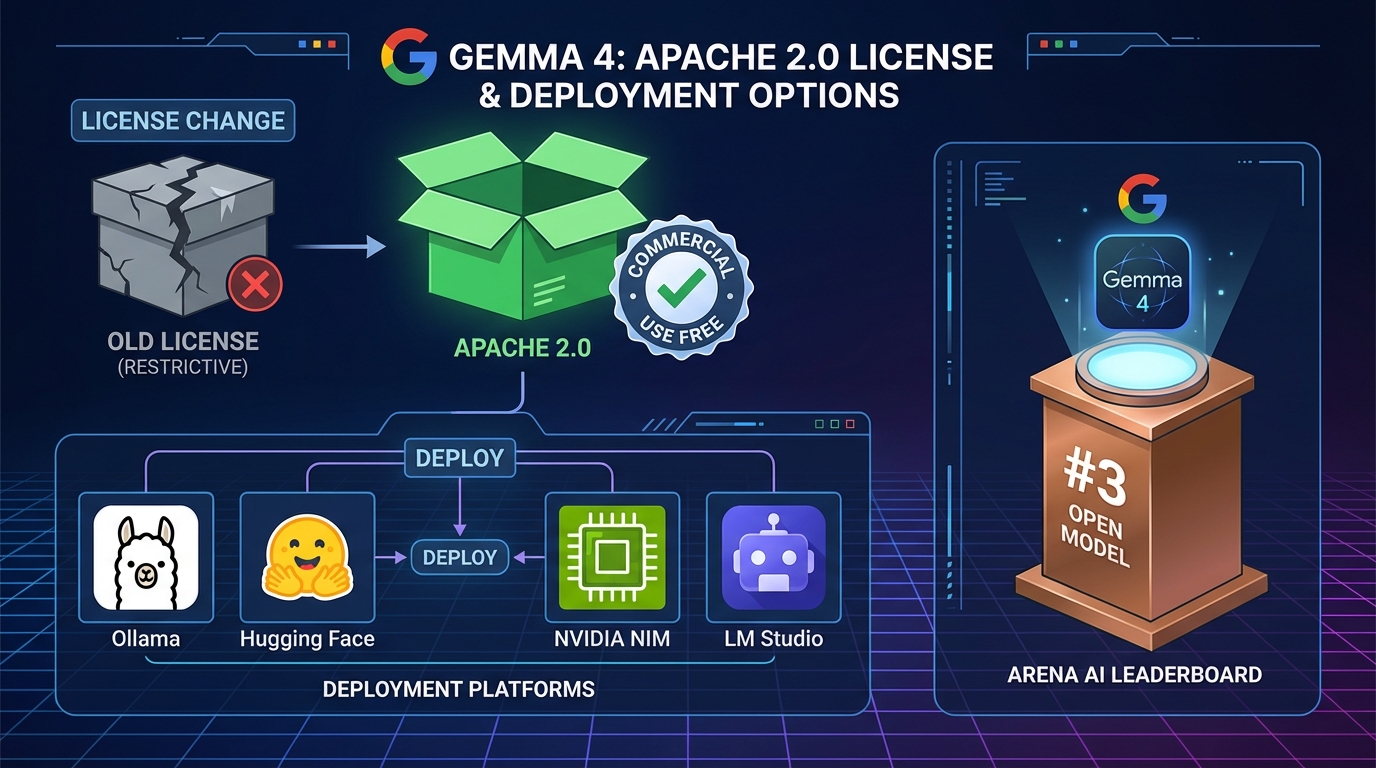
全モデルが画像とテキストのマルチモーダル入力に対応しており、エッジモデルはさらに音声入力にも対応しています。リリース当日からOllama・Hugging Face・NVIDIA NIM・LM Studioなど主要なプラットフォームでの利用が可能になっています。

Apache 2.0への変更がなぜ重要なのか
Gemma 4で最も注目すべき変化のひとつは、ライセンスがApache 2.0に変更されたことです。業界の専門家からは「ベンチマーク結果よりもこのライセンス変更の方が重要だ」という評価が相次いでいます。
旧来のGemmaライセンスは独自利用規約を持っており、ファインチューニングした派生モデルを商用製品に組み込む際のグレーゾーンが存在していました。Apache 2.0への移行によって、この曖昧さが完全に解消されます。具体的には次のことが自由になります。
- Gemma 4をベースにした製品・サービスの販売
- モデルの改変・ファインチューニングと商用展開
- 派生モデルの再配布
- Googleとの個別条件交渉なしでのプロダクション利用
これは企業がオープンモデルを採用する際の最大の障壁のひとつだった「法的リスク」を取り除くものです。スタートアップからエンタープライズまで、法務レビューのコストを大幅に削減しながらGemma 4を商用プロダクトの基盤として採用できるようになりました。
Apache 2.0ライセンスはOpenAIやMetaの一部モデルと同等の自由度を持つライセンスであり、オープンソースエコシステムとの親和性も高いです。CI/CDパイプラインへの組み込みや、社内向けLLMサービスの構築、SaaSへの組み込みといった用途でも安心して採用できます。
31Bモデルの実力とベンチマーク
Gemma 4 31BはArena AIのテキストリーダーボードにおいて、オープンモデルの中で世界3位にランクインしています。26B MoEモデルも同リーダーボードで世界6位を獲得しており、モデルサイズを大幅に上回る性能を発揮しています。「20倍のサイズのモデルを超える」というGoogleの発表は、実際のベンチマーク結果に裏付けられています。
256Kトークンというコンテキストウィンドウも実用上の大きな強みです。これは英語の長編小説1冊分を超えるテキスト量に相当します。ソフトウェアリポジトリ全体を一度にプロンプトへ渡したり、長大な法律文書や技術仕様書を丸ごと読み込んで質問に答えたりといったユースケースで真価を発揮します。
多言語対応も見逃せないポイントです。Gemma 4は140以上の言語でネイティブトレーニングされており、35以上の言語をアウトオブボックスで高精度にサポートしています。コミュニティによるテストでは、ドイツ語・アラビア語・ベトナム語・フランス語といった非英語タスクで競合モデルを上回る結果が報告されています。グローバル展開を見据えたサービス開発において、多言語対応のコストを大幅に下げられる可能性があります。
ファインチューニングの面では、NVIDIA DGX Sparkをリリース初日からサポートしており、ドメイン固有のデータを使った特化型モデルの構築も容易になっています。法律・医療・製造・金融など、専門知識が要求される領域での活用が期待されます。
マルチモーダル対応で広がるユースケース
Gemma 4の全モデルは画像とテキストのマルチモーダル入力に対応しており、エッジモデル(E2B/E4B)はさらに音声入力もネイティブサポートしています。単なるテキスト生成モデルから、視覚・聴覚を統合したインテリジェントなエージェントへと進化しています。
画像処理の面では可変解像度に対応しており、OCR(光学文字認識)やチャート・グラフの理解が得意です。これにより以下のようなユースケースが実現します。
- 請求書・領収書の自動読み取りと構造化データへの変換
- 技術図面・インフラ構成図の解析と説明生成
- スキャンされた文書のデジタル化とインデックス作成
- 製品検査ラインでの異常検知(オフライン環境でも動作)
エッジモデルの音声入力対応は、クラウドへのデータ送信が難しい環境での活用を大きく広げます。医療現場での問診支援、工場フロアでのハンズフリー操作、個人情報を含む音声データのオンデバイス処理など、プライバシー要件が厳しい領域でも安心して展開できます。
動画処理についても言及されており、フレームごとの分析だけでなく時系列での理解が可能です。セキュリティカメラ映像の分析や、製造ラインのリアルタイム監視といった用途への応用も考えられます。
エッジデバイスでの完全オフライン動作という特性は、ネットワーク遅延ゼロを求めるリアルタイムアプリケーション、インターネット接続が不安定な環境、そしてデータプライバシーが最優先のエンタープライズシナリオにおいて特に価値があります。
エンジニアが今すぐ試せる実行環境
Gemma 4はリリース初日から複数の主要プラットフォームで利用可能になっています。手元の環境に合わせて選べる豊富な選択肢が用意されています。
Ollamaでのローカル実行が最も手軽です。Ollamaのライブラリにgemma4が追加されており、ターミナルから数コマンドで動かせます。MacBook ProやLinuxワークステーションで素早く試したい場合に向いています。
Hugging Faceのリポジトリ(google/gemma-4-31B)からは重みファイルを直接ダウンロードでき、TransformersやLLaMA.cppとの組み合わせで細かい設定が可能です。ファインチューニングのベースモデルとして使う場合はこちらが標準的な選択肢です。
NVIDIA NIMでは gemma-4-31b-it がホステッドAPIとして提供されており、GPUを自前で用意せずにAPI経由でモデルを呼び出せます。プロトタイプ開発や性能評価に便利です。
LM StudioはGUIでモデルを管理・実行できるツールで、エンジニア以外のメンバーと共有する社内PoC環境の構築にも活用できます。UnslothからはGGUFフォーマットの量子化済みモデルも提供されており、メモリ効率を重視したローカル環境での運用に対応します。
Androidデバイス向けには AICore Developer Previewが公開されており、モバイルアプリへのGemma 4組み込みに向けた準備も進んでいます。
Gemma 4を採用する際の検討ポイント
Gemma 4は多くの魅力を持つモデルファミリーですが、プロダクション採用を検討する際にはいくつかの点を事前に評価しておくことが重要です。
まず推論速度の問題です。コミュニティのテスターから、31Bモデルは同一ハードウェア上でAlibabaのQwen 3.5と比較してスループットが約1/5になるという報告が出ています。これはGoogleが公式に認めた数値ではありませんが、レイテンシが重要なリアルタイムAPIや、コスト最適化が求められるハイスループットなバッチ処理を設計する際には、必ず実環境でのベンチマークを実施することをお勧めします。
モデル選択の観点では、用途に応じた使い分けが効果的です。長文ドキュメント処理や複雑な推論が必要な場合は256Kコンテキストを持つ31B/26Bが適しています。一方、リアルタイム性やプライバシー要件が厳しい場合、あるいはモバイル・IoTデバイスへの展開を考えている場合はE2B/E4Bの採用が現実的です。
ファインチューニングを前提とした採用では、Apache 2.0ライセンスのおかげで法務的な不確実性なくプロダクション展開できます。ただし、ファインチューニングデータの品質管理・バイアス評価・セキュリティテスト(プロンプトインジェクション対策など)は引き続き必要です。
コスト面では、モデルを自社インフラで運用する場合のGPUコスト、ファインチューニングのための計算リソース、そして推論速度に起因するスケールコストを総合的に試算することが大切です。特に大規模な商用サービスへの採用を検討する場合は、マネージドAPIとセルフホストの総コスト比較を入念に行うことを推奨します。
Gemma 4はApache 2.0ライセンスによる商用自由化、オープンモデルトップクラスの性能、マルチモーダル対応、そして幅広いエコシステムサポートを兼ね備えた、エンジニアにとって実践的な選択肢です。まずは手元の環境でOllamaを使った評価から始め、要件に合ったモデルサイズを見極めることをお勧めします。
























