



AIエージェントは各セッションで記憶がリセットされる揮発性の問題を抱えていますが、MEMORY.mdを活用することでセッション間の文脈を継続させることができます。本記事では、MEMORY.mdに書くべき情報・書くべきでない情報の分類から、情報の鮮度管理やセキュリティ観点まで、実践的な設計と運用手法を解説します。
なぜAIエージェントに「記憶」が必要なのか
Claude CodeやOpenClawのようなAIエージェントを日常的に利用していると、ある共通の悩みにぶつかります。それは「昨日話したことを今日は覚えていない」という問題です。LLM(大規模言語モデル)は本来、各セッションが独立しており、過去の会話内容をそのまま引き継ぐことができません。この揮発性の問題は、単なる不便さにとどまらず、プロダクション運用の現場で深刻な課題を引き起こします。
例えば、エンジニアがAIエージェントに「このプロジェクトではTypeScriptを使っている」「テストはJestで書く」「コードレビューではコメントを英語で書く」といった情報を伝えても、翌日の新しいセッションでは最初から説明し直す必要があります。これはチームの生産性を大きく損ないます。
AIエージェントのメモリは大きく3種類に分類されます。
メモリ種別 | 説明 | 例 |
|---|---|---|
長期記憶(Long-Term Memory) | セッションを跨いで保持される情報 | ユーザーの好み、プロジェクト知識 |
作業記憶(Working Memory) | 現在のタスク処理中のみ保持 | 実行中のタスク状態、一時変数 |
エピソード記憶(Episodic Memory) | 過去のインタラクションの記録 | 過去のバグ修正の経緯、決定の背景 |
MEMORY.mdが解決するのは主に「長期記憶」の問題です。2025年に発表されたA-MEMフレームワーク(NeurIPS 2025採択)の研究では、長期記憶を適切に管理することで、複数セッション対話の性能が+18.7%向上することが確認されています。AIエージェントの記憶設計は、今まさに最も注目される技術領域のひとつです。
MEMORY.mdの基本構造と4つのメモリタイプ
OpenclawやClaude CodeにおけるMEMORY.mdは、単なるメモファイルではありません。AIエージェントが次のセッションで最初に読み込む「記憶のインデックス」として機能します。重要なのは、MEMORY.md自体にはデータを詰め込まず、各記憶ファイルへのポインタ(参照)を管理するという設計原則です。
記憶ファイルは以下の4タイプに分類されます。それぞれのタイプに応じた情報を、別個のMarkdownファイルとして保存します。
タイプ | 保存内容 | 活用場面 |
|---|---|---|
user | ユーザーの役割・目標・知識レベル | 応答のトーンや説明の深さを調整 |
feedback | 作業アプローチへのガイダンス(成功・失敗両方) | 同じ指摘を繰り返さなくて済む |
project | 進行中の作業・目標・マイルストーン | プロジェクト背景を即時に把握 |
reference | 外部システムへのリンク・リソースの場所 | 関連ドキュメントや管理ツールへ即アクセス |
各メモリファイルは以下のフォーマットで記述します。
---
name: メモリ名
description: 1行の説明(将来の会話で関連性を判断するために使う)
type: user | feedback | project | reference
---
メモリ本文
(feedback/projectタイプは: 事実 → **Why:** 理由 → **How to apply:** 適用場面 の形式)
MEMORY.mdはこれらのファイルへのインデックスとして機能します。各エントリは1行150文字以内の短いフック(概要)でまとめ、詳細は別ファイルに委ねます。MEMORY.mdが200行を超えると後半が切り捨てられるため、簡潔さが求められます。
この「インデックス + 詳細ファイル」の2層構造がMEMORY.mdの核心です。インデックスにデータを書き込むとインデックスとして機能しなくなるという原則は、データベース設計と同じ発想です。
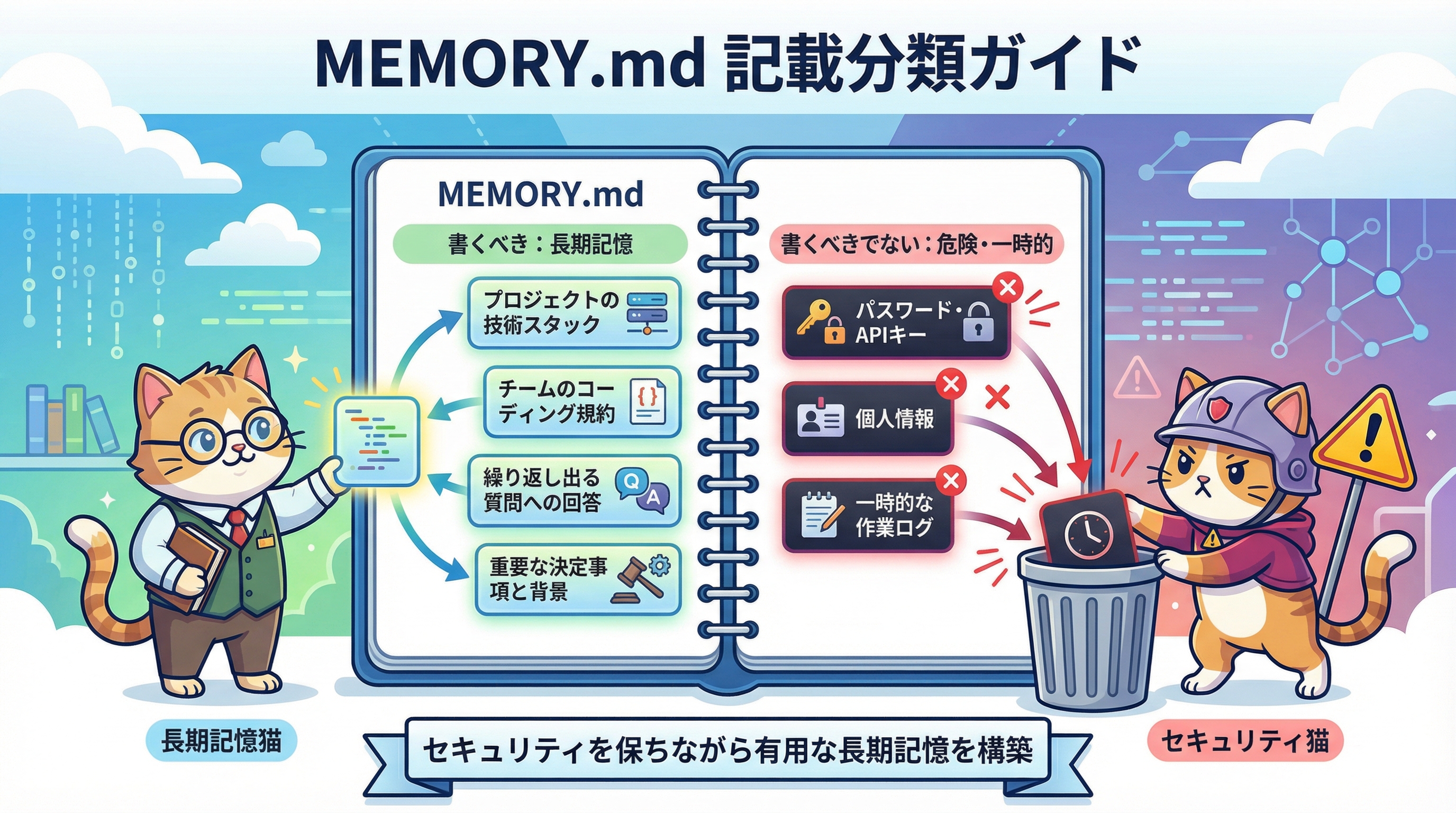
書くべき情報と書くべきでない情報の見極め方
MEMORY.mdを使い始めると、「どこまで書けばよいのか」という疑問が生じます。ここが最も重要な判断ポイントです。不要な情報を書き込み続けると、200行の制限内に本当に必要な記憶が入らなくなり、結果としてMEMORY.mdが機能しなくなります。
判断基準はシンプルです。「次のセッションでも必要な情報か」を問うことです。
書くべき情報の例
- ユーザーがGoに10年の経験を持ち、Reactは初心者である(フロントエンドの説明をバックエンド類推で行う)
- テストでデータベースをモックしない(過去に本番移行で不一致が発覚した教訓)
- バグトラッキングはLinearのプロジェクト「INGEST」で管理している
- マージフリーズが2026-04-10から始まる(モバイルリリースブランチのカット)
書くべきでない情報の例
- 特定の関数名・ファイルパス(コードから確認可能、リファクタリングで変わる)
- git履歴・最近のコミット内容(git logで確認可能)
- デバッグ解決策のレシピ(修正はコードに、理由はコミットメッセージに)
- 今日の作業メモ・進行中のタスク(セッション内のみで有効な一時情報)
- プロジェクトのアーキテクチャや慣習(コードを読めば分かる)
特に「今日の作業メモ」を書いてしまうパターンが多く見られます。一時情報を永続領域に書き込むと、情報が古くなってもそのまま残り、次のセッションで誤解を招きます。一時的な情報は別のノートファイルや会話内のメモで管理し、MEMORY.mdには普遍的な事実のみを書くよう心がけましょう。
また、宣言的に書くことも重要です。「〜した」という過去形ではなく、「〜になっている」という現在の状態を記録するスタイルが推奨されます。これにより、時間が経過しても情報の有効性を判断しやすくなります。
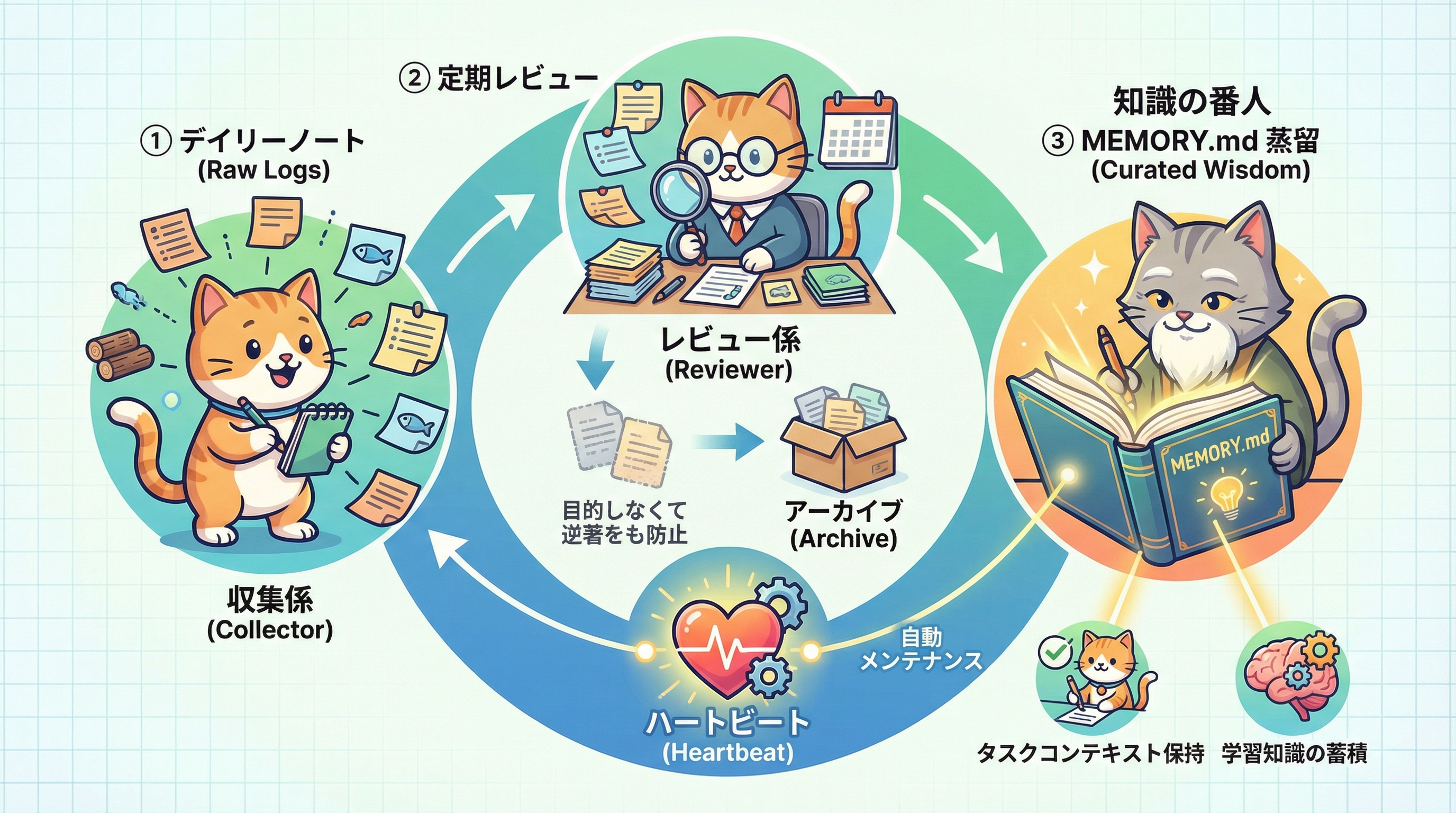
メモリの鮮度管理とメンテナンス戦略
MEMORY.mdを運用していくと、時間の経過とともにメモリが劣化する問題(Stale Memory)が発生します。例えば、「プロジェクトXはNode.js 18を使っている」という記憶が残っていても、実際にはNode.js 22に移行済みというケースです。古い記憶に基づいてAIが動作すると、誤ったアドバイスや実行ミスにつながります。
特定の関数名・ファイルパス・フラグを参照する記憶は、それが書かれた時点の情報です。リファクタリングや削除により、参照先が存在しなくなる可能性があります。メモリを使う前には必ず現在のコード状態を確認する習慣が必要です。
効果的なメンテナンス戦略として、以下を推奨します。
戦略 | 実施タイミング | 具体的な手順 |
|---|---|---|
定期レビュー | 月1回または大きな変更後 | MEMORY.mdの全エントリを確認し、古いものを削除・更新 |
参照先検証 | メモリを使う前 | ファイルパスはGlob、関数名はGrepで存在確認 |
競合解決 | 矛盾が発生したとき | メモリより現在のコード状態を優先し、メモリを更新 |
絶対日付変換 | プロジェクトメモリ保存時 | 「木曜日」→「2026-04-09」のように絶対日付で記録 |
OpenclawではCronジョブを活用してメモリのメンテナンスを自動化できます。例えば、週次でMEMORY.mdの内容とコードベースの乖離をチェックし、古くなったエントリをAIが自動的にフラグアップするような仕組みを構築することも可能です。
また、feedbackタイプのメモリは「成功した判断」も記録することが重要です。修正・指摘だけを保存していると、過去に検証済みの良いアプローチまで避けてしまう過剰抑制が起きます。「なぜその判断をしたか」の理由を残すことで、エッジケースでも適切に判断できるようになります。
セキュリティと運用上の注意点
MEMORY.mdはAIエージェントの長期記憶として機能するため、セキュリティ観点での慎重な運用が求められます。特にOpenclawのようなマルチエージェント・Slack連携環境では、複数のユーザーや外部サービスとの接点が増えるため、リスクの理解が重要です。
OWASP Top 10 for Agentic Applications(2025年12月9日リリース)では、AIエージェント特有のセキュリティリスクが体系化されています。その中でも特に注意すべきが「Lethal Trifecta(致命的な三重苦)」です。これは「機密データへのアクセス」「外部コンテンツへの露出」「外部通信能力」の3つが同時に存在するとき、プロンプトインジェクション攻撃の格好のターゲットになるというリスクです。
MEMORY.mdの運用における具体的なリスクと対策を以下にまとめます。
リスク | 具体例 | 対策 |
|---|---|---|
機密情報の蓄積 | APIキー・パスワードがメモリに記録される | 認証情報は環境変数で管理、メモリに書かない |
個人情報の漏洩 | グループSlackでの共有AIが個人情報を記録 | internal_reportタイプに機密情報禁止ルールを設定 |
メモリ汚染 | 外部コンテンツ経由でメモリに誤情報が挿入 | メモリ書き込み前に内容を検証するフックを設定 |
Stale Memoryによる誤動作 | 古いアーキテクチャ情報で誤った提案が生成される | 定期レビューと現在のコード状態との照合 |
グループチャットや複数ユーザーが同一AIエージェントを使う環境では、特別な注意が必要です。あるユーザーの個人情報や業務上の機密がMEMORY.mdに記録された場合、他のユーザーのセッションでもその情報が参照される可能性があります。チーム共有のエージェントでは、メモリに書く情報を「全員が知っていてよい情報」のみに限定するポリシーを設けることを推奨します。
また、CLAUDE.mdファイルに「機密情報はメモリに書かない」というルールを明示的に記載し、AIエージェント自身がメモリ書き込み時にそのルールを参照するよう設定することも効果的な対策です。
MEMORY.mdは正しく設計・運用することで、AIエージェントの生産性を大幅に向上させる強力なツールです。しかし、その効果は適切なメンテナンスとセキュリティ意識のもとで初めて発揮されます。「次のセッションでも必要か」「チーム全員が見ていい情報か」を判断基準として、賢明なメモリ設計を進めていきましょう。
























