



Claude Codeのコンテキスト喪失問題とは
Claude Codeを日常的に使っていると、ある問題にぶつかることがあります。昨日まで取り組んでいた機能の実装、議論した設計上のトレードオフ、途中まで書いたコードの意図——こういったコンテキストがセッションをまたぐと根こそぎ消えてしまうのです。
筆者も最初はこれを仕様として受け入れていました。「まあ毎回説明すればいいか」と思っていたのですが、長期プロジェクトで毎朝「前回の続きです。このリポジトリは〜」と書き続けるのはじわじわとストレスになります。CLAUDE.mdに記録を残す方法も試しましたが、手動で更新し続けるのも運用負荷がかかります。
そんな問題意識を持っていたところ、claude-memというOSSプラグインを見つけました。これはClaude CodeのフックAPIを活用して、セッション中の操作を自動的にキャプチャし、AIで圧縮したサマリを次回セッションに自動注入するツールです。Gemini CLIにも対応しているのが面白いところです。
ポイントは「手動で何かを記録する必要がない」という点です。インストールさえしてしまえば、あとは自動的に動き続けます。試してみると、この設計思想がいかに開発者体験に配慮されているかが分かりました。
claude-memのインストールと初期設定
インストールは驚くほど簡単です。ターミナルで以下のコマンドを実行するだけです。
# 最速インストール(推奨)
npx claude-mem install
# Gemini CLI 向け
npx claude-mem install --ide gemini-cliClaude Codeのプラグインマーケットプレイス経由でも導入できます。
# Claude Code内で実行
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem実際にインストールしてみると、単なるnpmパッケージのインストール以上のことが起きます。Claude Codeの設定ディレクトリにライフサイクルフックスクリプトが配置され、Bunランタイムのワーカーサービスが起動設定されます。ここが重要なポイントで、npm install -g claude-memだけでは動作しません——フックとワーカーサービスが揃って初めて機能します。
インストール後、http://localhost:37777にアクセスすると、メモリの状態をリアルタイムで確認できるWeb UIが立ち上がっています。保存されたセッションサマリや検索履歴がここで確認でき、「ちゃんと動いているか」を視覚的に把握できます。
初回実行時に~/.claude-mem/settings.jsonが自動生成されます。以下のような構造になっています。
{
"model": "claude-sonnet-4-6",
"workerPort": 37777,
"dataDirectory": "~/.claude-mem/data",
"logLevel": "info",
"contextInjection": {
"enabled": true,
"maxTokens": 2000,
"filterPatterns": []
}
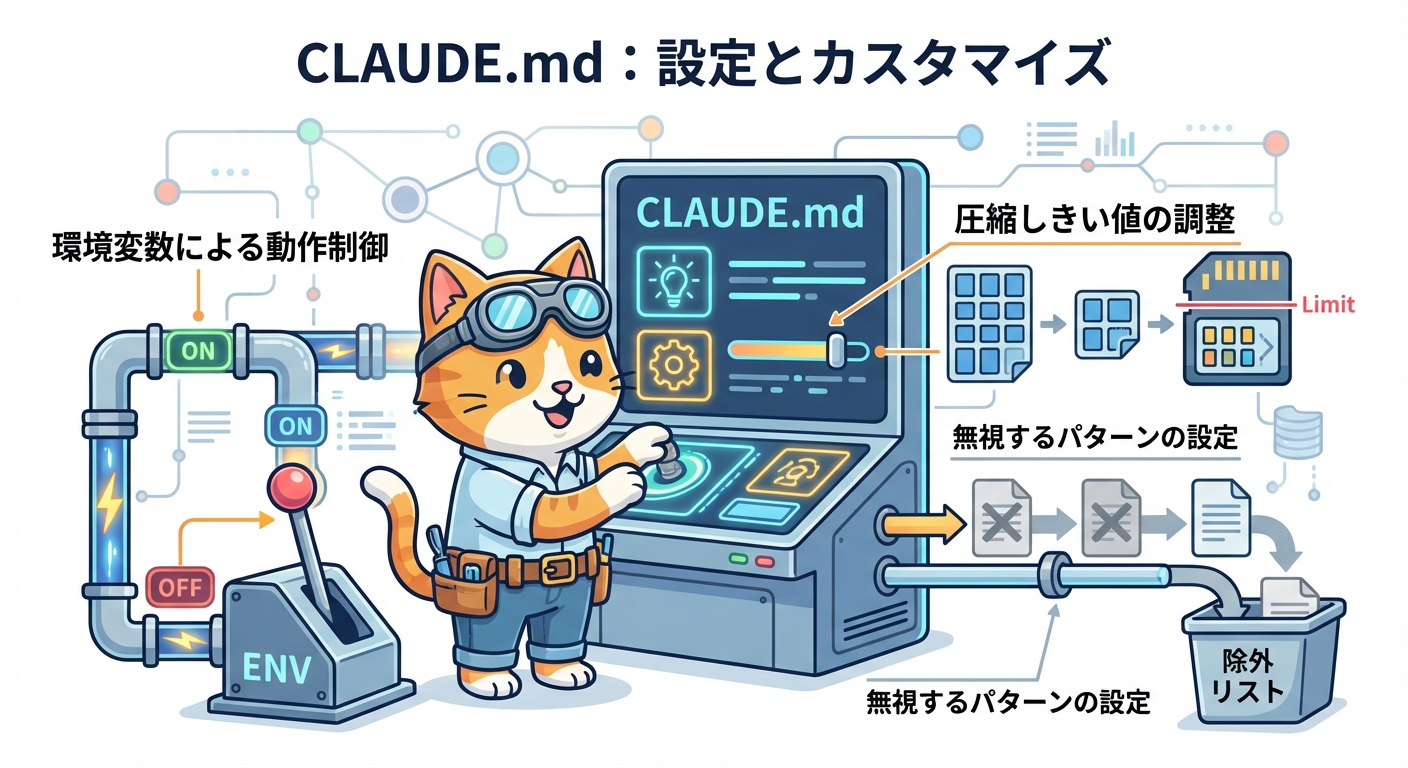
}AIモデルの選択、ポート番号、データ保存先、コンテキスト注入時の最大トークン数などを調整できます。デフォルト設定でも十分に動作しますが、コンテキストの粒度を細かく制御したい場合はここを調整することになります。
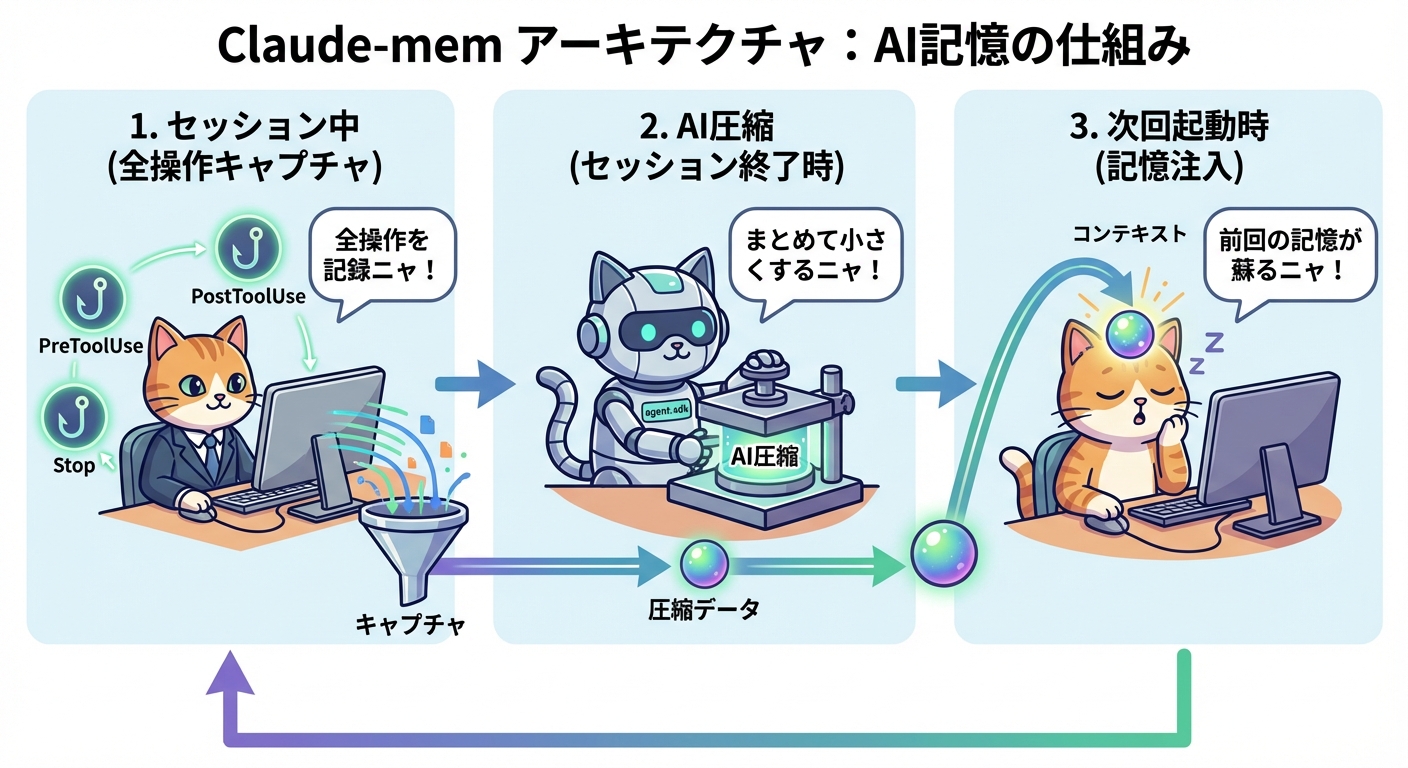
アーキテクチャを深堀りする フック・SQLite・Chromaの連携
claude-memの動作原理は、Claude Codeのフック機構を軸にした6コンポーネント構成です。それぞれの役割を詳しく見ていきます。
まず核となるのが5種類のライフサイクルフックです。
# フック種別と役割
SessionStart → 過去のコンテキストを関連度順で注入
UserPromptSubmit → ユーザー入力タイミングで前処理
PostToolUse → ツール呼び出し後の観察結果をキャプチャ
Stop → セッション停止時の処理
SessionEnd → AIによる圧縮・サマリ生成と保存PostToolUseフックが特に重要です。Claude Codeがファイルを読み書きしたり、コマンドを実行したりするたびに、その操作と結果が自動的に記録されます。「どのファイルをどう編集したか」「どんなエラーが出たか」「どう解決したか」——こういった情報が開発者の意識外で蓄積されていきます。
SessionEndフックでは、蓄積された観察結果をClaude's agent-sdkを使ってAIが意味的に圧縮します。単なる操作ログではなく、「このセッションで何を達成したか」「どんな決定を下したか」を人間が読んで理解できるサマリに変換します。
永続化にはSQLite(FTS5)を使用しています。FTS5(Full-Text Search 5)は全文検索エクステンションで、キーワード検索が高速に動作します。バンドル済みなので追加インストール不要です。
-- 内部的なテーブル構成(概念)
sessions → セッションメタデータ
observations → ツール使用の観察結果
summaries → AIが生成したセッションサマリセマンティック検索にはChromaというベクターデータベースを使用します。Pythonのuvパッケージマネージャーで管理され、FTS5によるキーワード検索と組み合わせたハイブリッド検索を実現します。「あの機能の実装」のような曖昧な検索でも関連するコンテキストを引き出せます。
ワーカーサービスはBunランタイムで動作し、ポート37777で10のHTTPエンドポイントを提供します。検索・取得・Web UIはすべてこのサービス経由で動作します。
トークン効率化の3層ワークフロー
claude-memの設計で特に感心したのがトークン効率化の仕組みです。過去のコンテキストをすべてそのまま注入するとトークンを大量消費してしまいます。これを解決するために、3段階の段階的取得(Progressive Disclosure)を採用しています。
Layer 1: search
└→ コンパクトなインデックス結果(~50-100トークン)
候補IDのリストを返す
Layer 2: timeline
└→ 時系列コンテキストで絞り込み
関連する時期のサマリを確認
Layer 3: get_observations
└→ 必要なIDの詳細のみ取得(~500-1,000トークン/件)
フルの観察結果を展開実際に動かしてみると、このアプローチの賢さが分かります。まず`search`で候補を絞り込み、必要なものだけ`get_observations`で詳細を取得するので、無駄なトークン消費が発生しません。ドキュメントによると、従来のアプローチと比べて約10倍のトークン節約になるとのことです。
MCPツールとして提供される3つのインターフェースは以下のとおりです。
# MCPツール一覧
mem:search → キーワード/セマンティック検索
mem:timeline → 時系列コンテキスト取得
mem:get_observations → 観察結果の詳細取得また、mem-searchスキルを使うと自然言語でメモリを検索できます。「先週実装した認証まわりの設計を教えて」といったクエリで、関連するセッション情報を引き出せます。この体験は予想以上に自然で、まるでAIが本当に記憶を持っているかのような感覚を覚えます。
設定・カスタマイズと実践的なTips
実際に運用してみて気づいた設定のポイントをいくつか紹介します。
プライバシー保護はAPIキーや認証情報を扱う場合に特に重要です。``タグで囲んだ内容はメモリに保存されません。 <private> このAPIキーは絶対に記録しないでください: sk-xxx </private> この実装は公開APIを使います。 コンテキスト注入の最大トークン数は用途によって調整する価値があります。短いタスクには少なめ、長期プロジェクトの継続作業には多めに設定すると効率的です。 { "contextInjection": { "enabled": true, "maxTokens": 3000, "filterPatterns": [ "node_modules", ".git", "*.log" ] } } filterPatternsには記録不要なパターンを正規表現で指定できます。大量のログファイルやビルド成果物の操作でメモリが汚染されるのを防ぎます。 Web UI(localhost:37777)でメモリの状態を確認する習慣をつけると、「何が記録されているか」を把握しやすくなります。不要なセッション情報を削除したり、サマリの品質を確認したりするのに便利です。 また、Gemini CLIとの共用も想定されています。異なるIDEで同じプロジェクトに取り組む場合も、同一のメモリストアを参照できます。 実際に使ってみて感じたこと 1週間ほど日常的に使ってみた感想をまとめます。 最も実感したのはセッション再開時のスムーズさです。朝Claude Codeを起動すると、昨日取り組んでいた内容のサマリが自動的に注入されています。「昨日はこのAPIエンドポイントの実装を途中まで進めた。認証フローでXXXの問題があり、YYYアプローチで対処中」といった情報がすでにコンテキストにある状態で作業を再開できます。 もちろん完璧ではありません。AIによる圧縮の粒度は状況によって変わりますし、すべての詳細が保存されるわけではありません。しかし「ゼロから説明し直す」よりは格段に効率的です。 技術的に面白いと思ったのは、Claude's agent-sdkをAI圧縮エンジンとして使っている点です。LLMそのものが別のLLMの記憶を整理するという構造は、エージェント設計の観点から参考になります。 注意点として、ライセンスはAGPL-3.0です。商用プロジェクトでの利用には確認が必要です。またragtime/ディレクトリはPolyForm Noncommercial Licenseと異なるライセンスが適用されているため、用途によっては注意が必要です。 Claude Codeを長期プロジェクトで活用している方、またはセッション間のコンテキスト継続に課題を感じている方には、試す価値のあるツールだと感じています。インストールはコマンド1つで完了するので、まず動かしてみることをおすすめします。
























