


2026年4月9日、GoogleとIntelが複数世代にわたるAI基盤インフラのマルチイヤー拡大提携を正式発表しました。両社はすでに約20年の取引関係を持ち、IPU(Infrastructure Processing Unit)領域では2022年から共同開発を続けてきました。今回の提携はその延長線上に位置しますが、AI推論市場が急拡大するなかでシリコン選定の方向性を大きく塗り替える可能性を秘めています。インフラ設計・クラウド選定に関わるエンジニア・アーキテクトにとって、この提携が持つ意味を正確に理解しておくことが重要です。
マルチイヤー提携の全貌
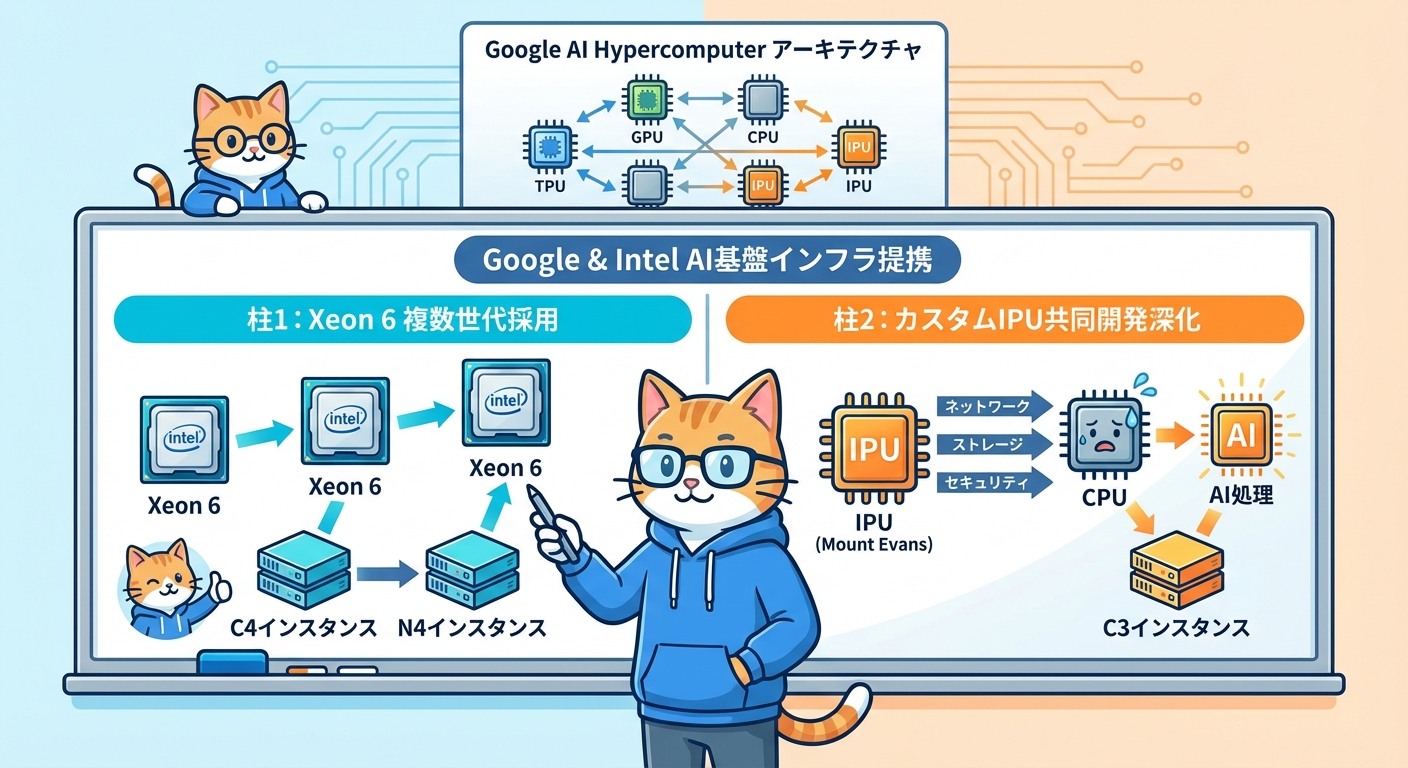
今回の提携の核心は2つの柱から成ります。
第1の柱は、Intel Xeon 6プロセッサの複数世代コミットメントです。Google CloudはすでにIntel Xeon 6を搭載したC4・N4インスタンスを展開していますが、今回の提携でさらに複数世代にわたってXeon CPUを継続採用することを明示的に約束しました。AI推論から汎用コンピューティングまで、幅広いワークロードをXeon基盤でカバーする構想です。
第2の柱は、カスタムIPU(Infrastructure Processing Unit)の共同開発深化です。両社は2022年から共同開発を続けており、Google CloudのC3インスタンス向けに「Mount Evans」というASICベースのIPUをすでに実装しています。IPUはネットワーキング・ストレージ管理・セキュリティ処理といった基盤機能をホストCPUからオフロードし、CPU資源をAI・アプリワークロードに集中させる役割を担います。今回の提携でこのIPU共同開発をさらに拡大することが確認されています(具体的なタイムライン・性能目標は非公開)。
この提携の背景には、AIのメインストリームが「モデル学習」から「推論・デプロイ」フェーズへと急速にシフトしている現実があります。NVIDIAのGPUはトレーニングで圧倒的な地位を持ちますが、推論フェーズでは必ずしもGPUが最適解ではなく、コストとスループットのバランスを取った多様なシリコン選択が現実的になってきました。
GoogleとIntelそれぞれの戦略的メリット
Googleにとってのメリット
Googleは今回の提携によって複数の戦略的目標を実現できます。
最も大きいのはベンダー依存リスクの構造的な分散です。GoogleはTPU(自社開発のIronwood含む)・NVIDIA GPU・AMD GPU・Intel Xeonという複数のシリコンを組み合わせたヘテロジニアスコンピューティング戦略を採用しており、Intelとの長期コミットはこの戦略の重要ピースとなります。単一ベンダーへの依存を避けることで、調達リスクと価格交渉力の両面でメリットが生まれます。
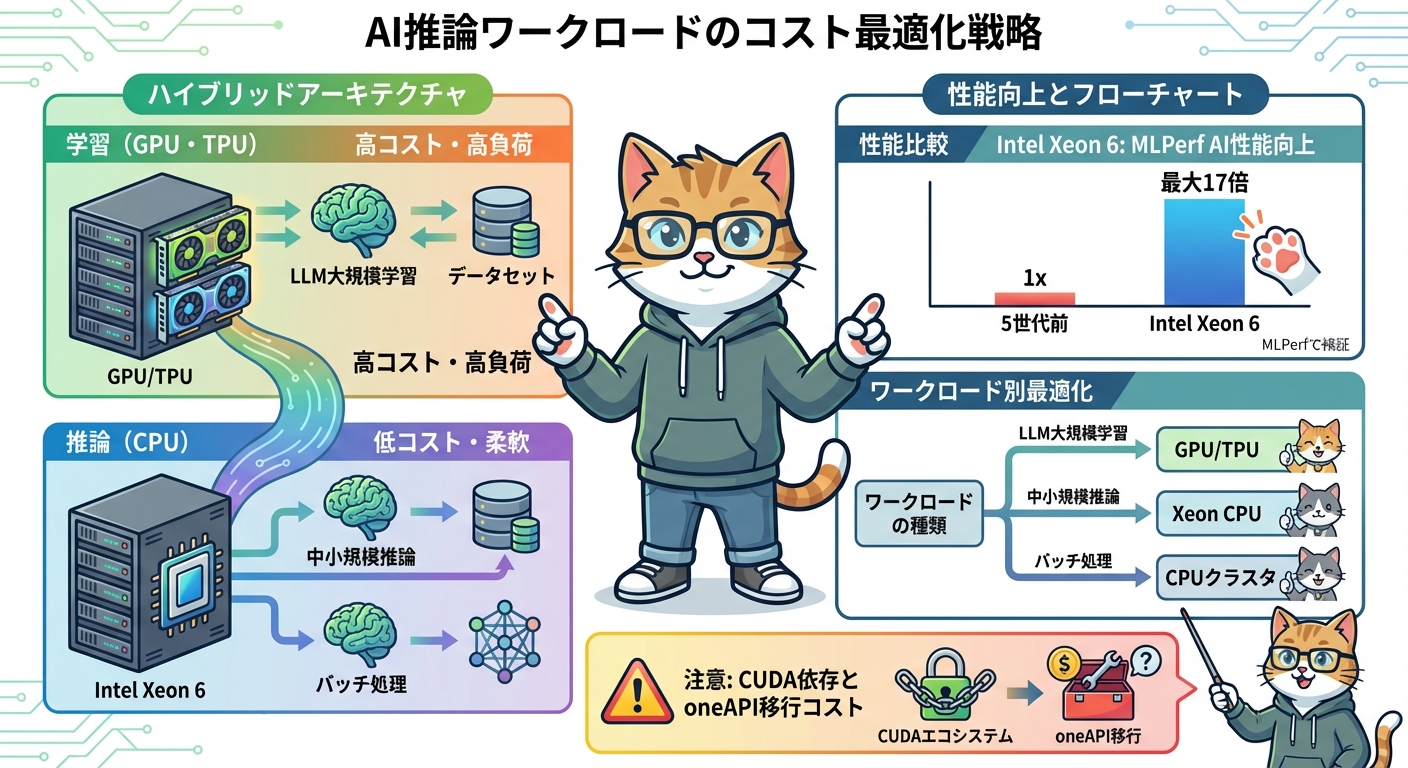
次に推論フェーズでのTCO(総保有コスト)最適化です。Intel Xeon 6は5世代前のサーバーと比べて平均5対1(最大10対1)のサーバー統合率を実現し、TCOを最大68%削減できるとIntelは公表しています。MLPerf Inference v6.0でもスケーラブルなオープンAI性能を達成しており、軽量から中規模の推論タスクをCPU環境で処理することで、GPU/TPU依存のコスト構造を変えられます。
さらにAI Hypercomputerアーキテクチャへの統合も重要です。GoogleはTPU(Ironwood)・GPU・CPU・高性能ファブリックを統合したAI Hypercomputerアーキテクチャを推進しており、XeonはこのHypercomputer内でオーケストレーションレイヤーとして機能します。
Intelにとってのメリット
Intel側にとってこの提携は、まさに復活戦略の要石です。CEO Lip-Bu Tan(2025年就任)のもとで「Foundry First戦略」と「AI推論特化」への転換を進めるIntelにとって、Googleというハイパースケーラーとのマルチイヤー契約は信用力として計り知れない価値があります。
Google Cloud規模での実稼働実績は、Xeon 6がAI推論・汎用ワークロードで通用することを市場全体に示すショーケースとなります。また、カスタムIPU(Mount Evans)の共同設計・製造実績はIntel Foundry Servicesのファウンドリ事業強化にも直結し、TSMCへの対抗軸を作る上でも重要な一手となります。
NVIDIAへの対抗軸としての位置づけ
今回の提携はNVIDIAへの直接対決という構図ではなく、「CPU+カスタムASIC」による推論コスト最適化という切り口での市場分断を狙ったものです。
NVIDIAのH100/Blackwell系GPUはAIトレーニング市場を事実上独占していますが、供給制約・高価格・CUDAエコシステムへの依存という課題も抱えています。GoogleをはじめとするハイパースケーラーがNVIDIA依存の低減を戦略的優先課題としていることは、業界内でも広く認識されています。
GoogleはTPU(Ironwood)・Xeon CPU・IPUの組み合わせで、NVIDIAのGPUクラスタに依存しない独自のAI基盤を構築しつつあります。AIのユースケースが推論フェーズ中心になるにつれて、「高性能だが高コストなNVIDIA GPU」よりも「推論に最適化された安価なCPUやカスタムチップ」の需要が拡大する構造が生まれています。
IntelのロードマップでもNVIDIA対抗の意図が見えます。Gaudi 3・Xeon 6に続き、2026年後半には推論特化の次世代AI GPU「Crescent Island」(Xe3Pアーキテクチャ・160GB LPDDR5X搭載・エアクール対応)のカスタマーサンプリングが始まる予定です。さらにその後継として「Jaguar Shores」(HBM4E搭載・2027年想定)が控えており、NVIDIAやAMDに対して年次リリースサイクルで競争する姿勢を明確にしています。
ただし、最大の課題はソフトウェアエコシステムです。NVIDIAの強みの本質はCUDAであり、開発者の多くはCUDAファーストで実装しています。IntelのoneAPIやGaudi向けSDKへの移行コストは依然として高く、ハードウェア性能だけで差別化するのは容易ではありません。この点はIntelが最も克服しなければならない壁であり、エンジニアとして評価する際にも重要な留意点です。
インフラ選定・コスト設計への実務インパクト
この提携と技術動向はエンジニア・アーキテクトの日常業務に具体的な影響をもたらします。
CPU推論の再評価
「AIワークロード=GPU必須」という前提が変わりつつあります。Intel Xeon 6は5世代前比でAI推論性能が最大17倍向上しており(MLPerf Inference v6.0実績)、軽量モデルや中規模推論タスクはCPUインスタンスで十分対応できるケースが増えています。
Google CloudのC4・N4インスタンス(Xeon 6ベース)を使えば、GPU/TPUに比べて大幅に安価なコストでAI推論ワークロードをテストできます。まず自社の推論タスクをCPU環境で検証し、性能要件を満たすかどうか確認するアプローチが有効です。
ハイブリッド設計という選択肢
実務での設計指針として「学習はGPU/TPU、推論はXeon CPU」というハイブリッドアーキテクチャが現実的な選択肢として浮上しています。以下のようなワークロード分類が実務上の出発点になります。
- LLM学習(大規模)→ GPU(NVIDIA H100/Blackwell またはGoogle TPU Ironwood)が引き続き主力
- LLM推論(中小規模モデル)→ Xeon 6 CPUインスタンスでコスト削減を検討する余地あり
- 汎用バッチ推論 → CPUクラスタ+Xeon 6で低コスト運用が現実的に
- リアルタイム高スループット推論 → GPU or TPUが引き続き優位
- エッジ・エンタープライズAI → Intel Gaudi 3 / Crescent Island(2026年後半〜)が選択肢に加わる
ソフトウェアスタックへの注意点
IntelのAIワークロードはoneAPIやOpenVINOでの最適化が前提となります。CUDA依存のコードをそのまま動かすことはできず、移植コストの見積もりが必要です。特にGaudi向けワークロードは独自SDKの学習コストを事前に考慮しておくことが重要です。oneAPIのエコシステムはCUDAと比べてまだ成熟度に差があるため、採用判断の際はソフトウェア面の工数も含めてTCOを評価することをお勧めします。
今後のロードマップと注目ポイント
エンジニア・アーキテクトとしてウォッチすべきマイルストーンを整理します。
2026年後半は最初の重要なタイミングです。Intelの次世代AI推論GPU「Crescent Island」のカスタマーサンプリングが始まります。Xe3Pアーキテクチャ・160GB LPDDR5X搭載・エアクール対応で設計されており、エンタープライズサーバー向けの推論特化GPUとして市場投入されます。Google CloudのXeon 6展開も継続的に拡大する見込みです。また、Intelが進めるIntel 18A(1.8nmプロセス)製造の立ち上げも注目ポイントで、RibbonFETとPowerVia技術の実装によって製造競争力の回復を目指しています。
2027年にはIntel GPU年次更新サイクルの試金石として「Jaguar Shores」(HBM4E搭載)の登場が見込まれています。Intelが本当に年次GPU更新サイクルを維持できるか、ソフトウェアエコシステムの成熟が追いつくかどうかが、NVIDIAへの対抗軸として機能するかの分岐点になります。
また、競合動向としてAMD MI350も見逃せません。2025年中盤に登場し、288GB HBM3E搭載でMicrosoft・Meta・OpenAIへのデプロイメントコミットをすでに獲得しています。NVIDIA・Intel・AMDの三つどもえの推論市場競争が本格化するなか、クラウドインフラ選定の判断材料は今後さらに増えていきます。
いずれにせよ、GoogleとIntelの提携強化は「AIインフラはGPU一択」という時代に終止符を打つ動きの象徴といえます。推論フェーズ中心のAI活用が広がる現在、CPU・カスタムASIC・GPU・TPUを適材適所で組み合わせるヘテロジニアスアーキテクチャへの理解がインフラ設計者の必須スキルになりつつあります。今後のシリコン動向を継続的にウォッチし、自社ワークロードに最適な選択ができる体制を整えておきましょう。
























