



2026年5月28日、AWS は次世代の AWS Resilience Hub を商用リージョンで一般提供開始しました。生成 AI を活用した障害モード分析と、システムやサービス、ユーザージャーニーという新しいアプリケーションモデルを軸に、レジリエンス運用そのものを再設計するアップデートです。AWS Japan のニュースブログでも同日に「生成 AI ベースの SRE レジリエンス・ジャーニー」として紹介されました。
サーバーレスやコンテナ、マイクロサービスを束ねたクラウドネイティブな本番環境では、システムの依存関係が把握しにくく、定期的なディザスタリカバリ訓練だけでは見落としが残りがちです。次世代版は、依存関係の自動検出と生成 AI による潜在障害モードの洗い出しをつなげることで、SRE や開発リーダーがビジネスにとって重要なユーザージャーニー単位で投資判断できる足場を用意します。
本記事では一次情報として AWS の公式ブログを起点に、新しいアプリケーションモデルと依存関係検出、生成 AI 障害モード分析、AWS Organizations 連携、導入ステップ、新しい課金モデルの順で整理します。本ブログで明示されていない数値や具体的なリージョン名、生成 AI のバックエンドモデル名には踏み込まず、確かな範囲で運用視点を語ります。
次世代 AWS Resilience Hub が変えるレジリエンス運用の前提
AWS Resilience Hub は、これまでアプリケーション単位で復旧目標と評価結果を管理するサービスとして提供されてきました。次世代版では、ビジネス全体を俯瞰できる単位での再構成と、生成 AI を組み合わせた評価が中心に据えられています。AWS のブログでは「生成 AI ベースの SRE レジリエンス・ジャーニーを支援する」と位置付けられており、単発の評価ツールではなく、継続的な改善サイクルを伴走する基盤として再設計されたことが分かります。
提供範囲は「Resilience Hub が利用可能な AWS 商用リージョン」とされており、具体的なリージョン一覧は AWS Capabilities by Region を参照する建付けです。利用開始時点ではすでに既存ユーザーが多く存在するため、AWS は既存アプリケーションと評価ポリシーを新モデルに寄せる移行 API も合わせて提供しています。次世代版は刷新であると同時に、既存資産を活かして移行できる導線も用意された形です。
SRE や開発リーダーにとっての意味は明確です。アーキテクチャを横断したリスクと優先順位を、属人的な PowerPoint ではなく共通プラットフォーム上で扱えるようになり、ユーザージャーニー単位の SLO とディザスタリカバリ要件を一枚岩で議論しやすくなります。記事の以降のセクションでは、その新しい構造と運用の流れを順に追っていきます。
新しいアプリケーションモデルと依存関係検出の仕組み
次世代 AWS Resilience Hub では、最上位にビジネスアプリケーションを表す「システム」が置かれ、その配下に複数の「サービス」が並びます。さらに、エンドユーザーが体験する重要な経路を「ユーザージャーニー」として定義する構造です。たとえば EC サイトであれば、商品検索、カート、決済、注文確認といった一連の流れがユーザージャーニーになり、SLO や復旧優先度を業務文脈で議論しやすくなります。
サービスの単位では、AWS リソースをタグ、AWS CloudFormation スタック、Terraform の状態、Amazon EKS のクラスター情報などから特定できます。インフラの管理スタイルが複数に分かれていても、サービスという論理単位で束ねられるため、Infrastructure as Code とランタイムの両方を起点に構成図を描けるのが特徴です。
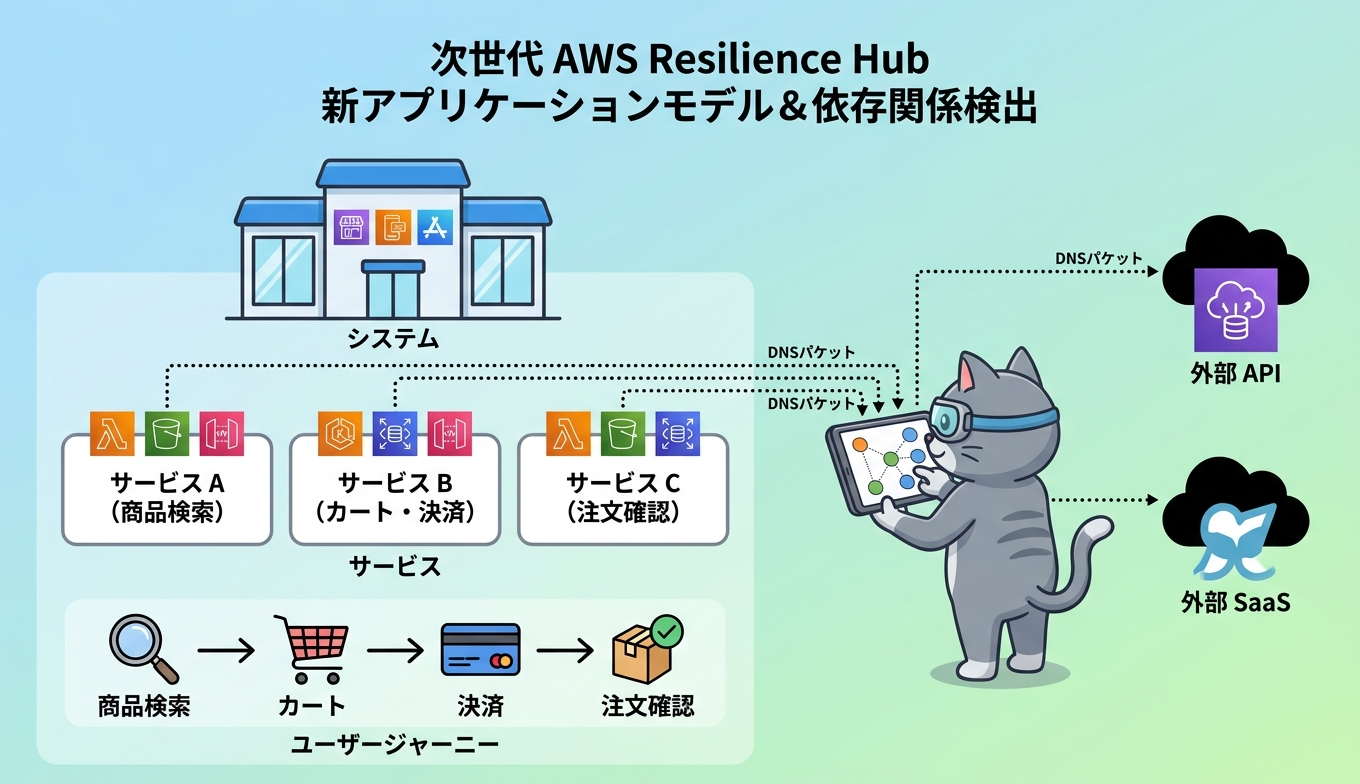
依存関係検出は自動評価として用意されており、AWS サービスや内部エンドポイント、サードパーティのエンドポイントを DNS クエリログ分析で洗い出します。VPC のクエリログを情報源にしているため、コードからは見えにくい外部 API 呼び出しや、隠れた共有サービスとの結合度を可視化できるのが利点です。検出した依存関係は、後段の障害モード評価でも活用されます。
旧来のアプリケーション単位の構造から見ると、複数の旧アプリケーションが、ひとつのシステムと複数のサービスへ集約されるイメージになります。AWS は既存ユーザー向けに移行 API を提供しており、既存の評価ポリシーを新しいレジリエンスポリシーに変換し、既存アプリケーションを新モデルへマッピングできます。組織のドメイン分割を見直しつつ、過去の評価資産を捨てずに次世代版へ寄せられる点は実務上の安心材料です。
生成 AI による障害モード分析とモジュール型レジリエンスポリシー
新サービスの中核は、生成 AI を活用した障害モード分析です。AWS Resilience Hub はサービスごとに Failure Mode Assessment を実行し、依存関係検出で把握した構成と組み合わせて、潜在的な障害シナリオを提示します。SRE が経験則で挙げてきた「冗長化の穴」や「DR の盲点」を、機械的な網羅性で洗い直す位置付けです。なお、本ブログでは生成 AI のバックエンドとなる具体的なモデル名は明示されていないため、ここでは機能としての価値に絞って捉えます。
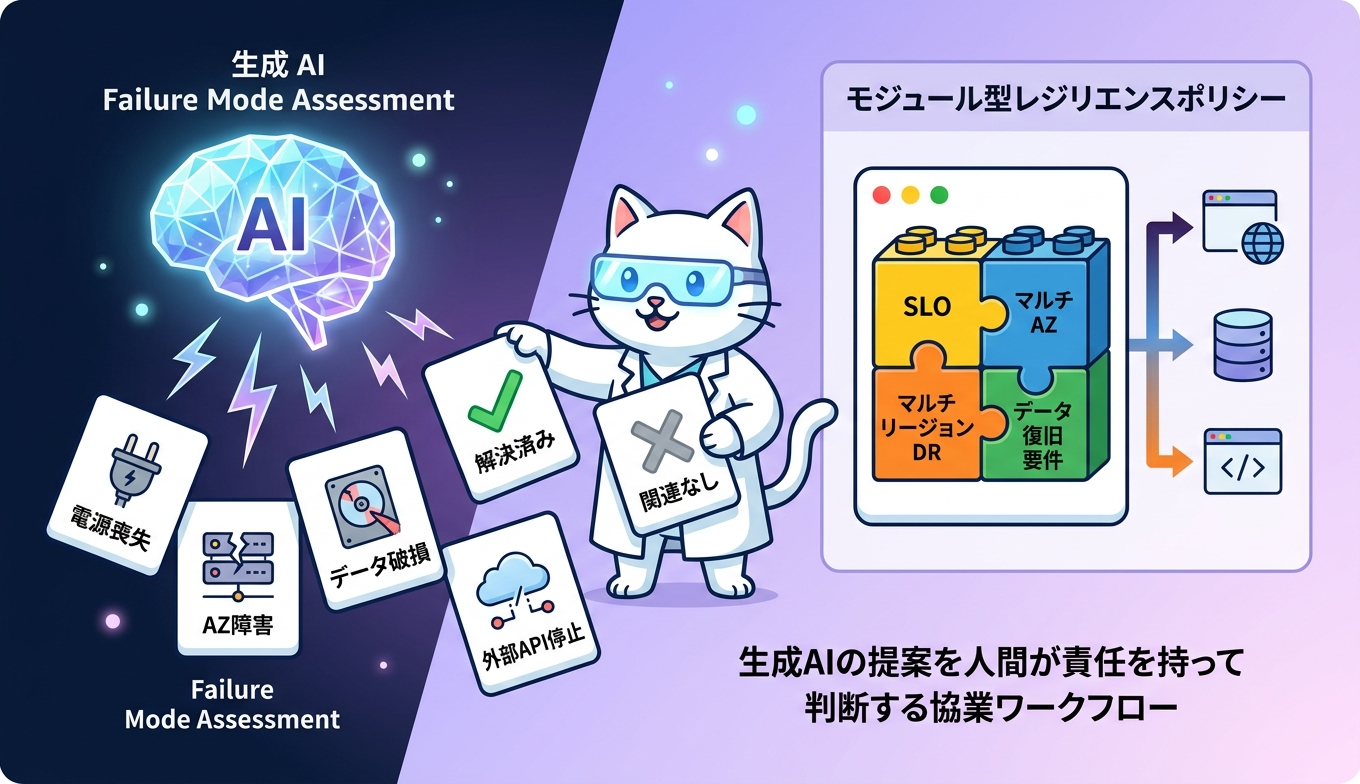
評価の前提となるレジリエンスポリシーは、モジュール型として設計されています。SLO、マルチ AZ 構成、マルチリージョンディザスタリカバリ、データ復旧要件といった要素を組み合わせて、サービスごとに必要な水準を宣言します。すべてのサービスを同じ厳しさで縛るのではなく、ユーザージャーニーごとに重要度を変えられるため、コストとリスクのバランスを取りやすい構造です。
障害モード評価の結果は、resolved や irrelevant として印を付けながらレビューしていきます。実装で対処済みのもの、設計判断として受容するもの、当該サービスには無関係なもの、追加投資が必要なもの、と仕分けることで、SRE チームのバックログにそのまま接続できます。生成 AI が提示する候補を、人間が責任を持って判断するワークフローが組み込まれているのがポイントです。
運用面では、ポリシーをモジュール部品の集合として共通化しておくと、新しいサービスを立ち上げた際にもテンプレートのように適用できます。プラットフォームチームが基準ポリシーを束ね、各プロダクトチームが必要な追加要件だけを差し込む形にすることで、組織全体のレジリエンス基準を底上げしやすくなります。
AWS Organizations 連携で実現する組織横断レジリエンス管理
企業全体のレジリエンスを管理する仕組みとして、次世代 AWS Resilience Hub は AWS Organizations との連携を備えています。単一の委任管理者アカウントから、組織全体のシステムとサービスを横断的に扱えるようになり、個々のアカウントへログインせずに体制を評価できる点が大きな違いです。複数事業部や子会社で AWS アカウントが分散している環境ほど、効果が出やすい構造になっています。
権限付与のパターンとしては、AWS Organizations を使う場合のサービスリンクロール(SLR)と、Organizations を使わない場合のクロスアカウントロールという 2 系統が想定されています。組織として委任管理者を整備していれば SLR ベースで素直に組み込めますし、まだ Organizations 中心の運用に踏み切れていない環境でも、クロスアカウントロールを介して既存のガバナンス境界を保ちながら導入できます。
組織全体レポートは、その上に乗ります。委任管理者アカウントから企業全体の評価結果と改善状況をまとめて閲覧できるため、SRE 部門だけでなく、CISO やプラットフォーム責任者、事業責任者が共通のダッシュボードでレジリエンス投資の進捗を確認しやすくなります。アカウントごとに別管理だった指標を統合し、四半期レビューや経営報告の素材として使える点は、ガバナンス強化のうえで実用的です。
ポリシーからシステム評価までの導入ステップ
導入の初期準備として、Invoker IAM ロールの設定が必要です。このロールにより、AWS Resilience Hub は AWS リソースに対する読み取り専用アクセスを取得し、クロスアカウントロールやサービスリンクロールを介して、組織横断での評価を実施できます。最初に最小権限のテンプレートを整え、セキュリティチームのレビューを通しておくと、後続の展開がスムーズになります。
次に、AWS マネジメントコンソールから Create policy でレジリエンスポリシーを作成します。SLO、マルチ AZ、マルチリージョン DR、データ復旧要件といったモジュールを必要な分だけ組み合わせ、サービスに割り当てる基準を準備します。ここまでが、評価対象を受け入れるための土台です。
続いて、ビジネスアプリケーションを表すシステムを作成し、その配下にサービスを定義します。タグ、AWS CloudFormation、Terraform、Amazon EKS などからリソースを特定し、サービスの実体を結び付けます。最後に、依存関係検出を有効化し、障害モード評価を実行する流れです。主な手順は次のとおりです。
- Invoker IAM ロールと必要なクロスアカウントロールを準備し、最小権限で読み取りアクセスを与えます。
- レジリエンスポリシーを作成し、SLO とディザスタリカバリ要件のモジュールを組み合わせます。
- システムとサービスを定義し、依存関係検出と障害モード評価を実行して結果を resolved または irrelevant でレビューします。
評価結果のレビューはチーム横断で行うことが望ましく、SRE、アプリケーション開発、セキュリティの三者でレビュー会を定例化すると、検出された障害モードが運用改善や設計レビューの議題として自然に流れます。
新しいサービス課金モデルと SRE が取るべき次の一手
新しい課金モデルは、サービス単位の料金体系です。各サービスに月 2 回の障害モード評価が含まれ、必要に応じてオプションとして自動依存関係評価を追加できる形になっています。AWS Resilience Hub には無料枠も用意されており、まずはコストを抑えて試行できる構造です。具体的な金額は環境やリージョンによって異なるため、本記事では踏み込まず、公式の料金ページで最新の値を確認していただくのが確実です。
既存ユーザーにとっての次の一手は明確です。移行 API を活用し、旧アプリケーションと評価ポリシーを新モデルへ寄せていく作業を、優先度の高いサービスから順に進めるアプローチが現実的です。一度に全社一括で切り替えるのではなく、最もクリティカルなユーザージャーニーから着手し、評価サイクルを回しながら横展開していくと、運用への負荷を抑えられます。
新規に取り組む組織であれば、まず売上や顧客体験に直結するユーザージャーニーをひとつ選び、そのジャーニーに紐づくシステムとサービスを定義するところから始めるのが現実的です。生成 AI 障害モード分析と組織全体レポートを実際に動かしてみることで、自社のレジリエンス成熟度を客観的に測れます。SRE チームとプラットフォームチームが共通言語として使える基盤として、次世代 AWS Resilience Hub は早めに触れておく価値があります。
参考として AWS Japan のニュースブログ 次世代 AWS Resilience Hub のご紹介 と、英語原文 Introducing the next generation of AWS Resilience Hub をご確認ください。
























