



Amazon S3 Filesとは何か
Amazon S3 Filesは、2026年4月7日にAWSが一般提供(GA)を開始した新機能です。一言で表すと、「Amazon S3バケットをNFSファイルシステムとしてマウントできるようにする」サービスです。
これまでのAmazon S3はオブジェクトストレージとして高い耐久性・スケーラビリティ・コスト効率を誇ってきましたが、Linux/WindowsのOSが標準で扱うファイルシステムとしては利用できませんでした。S3のデータにアクセスするためには、AWS SDKやCLIを通じたAPIコールが必要でした。
Amazon S3 Filesはこの課題を解決します。Amazon EFSをベースに構築されており、S3バケット内のデータにファイルシステムのセマンティクスで直接アクセスできるようになります。現在、34のAWSリージョンで利用可能です。
EC2インスタンスやLambda関数、EKS上のコンテナから、まるでローカルディスクを扱うような感覚でS3のデータを読み書きできます。標準のPythonライブラリ、MLフレームワーク、CLIユーティリティ、シェルスクリプトなど、既存のファイルシステムツールがそのまま動作するのが最大の特長です。
従来のS3との違いとアーキテクチャの仕組み
従来のS3と、S3 Filesが何を変えるのかを理解するために、まずそれぞれのアクセス方式を整理しましょう。
従来のAmazon S3は「オブジェクトストレージ」として設計されています。データはオブジェクトキーで識別され、AWS SDKやAWS CLIを使ったAPIコールでしかアクセスできません。ファイルのオープン・クローズ・シークといったファイルシステム操作には直接対応しておらず、Pythonのopenやシェルのcpコマンドなどをそのまま使うことはできませんでした。
S3 Filesはこの制約を取り除きます。具体的な技術的仕組みは以下のとおりです。
プロトコル
NFS v4.2とv4.1に対応しており、POSIX権限・ファイルロック・読み取り後書き込み整合性(read-after-write consistency)といったファイルシステムセマンティクスをサポートします。複数のコンピューティングリソースが同じデータを同時に読み書きするNFS close-to-open整合性も確保されています。
インテリジェントキャッシング
S3 Filesは「高性能ストレージ」と呼ばれるキャッシュ層を持ちます。デフォルトでは128KB未満のファイルはこの高性能ストレージから低レイテンシーで提供されます。一方、1MB以上のシーケンシャル読み取りについては「リードバイパス」機能が働き、高性能ストレージを経由せずにS3から直接並列GETリクエストでデータをストリームします。この仕組みにより、1クライアントあたり最大3GB/sのスループット、複数クライアント合計では4TB/s以上の集約スループットを実現します。
データの同期
ファイルシステムへの書き込みはS3バケットに自動同期されます。逆に、S3バケットへ直接アップロードされたデータもファイルシステムに反映されます。アクティブでないデータは設定した保持期間(1〜365日、デフォルト30日)が経過すると高性能ストレージから自動削除され、コストが抑えられます。
主要コンポーネント
- ファイルシステム — S3バケットにリンクされた共有ファイルシステムのエンティティ
- マウントターゲット — VPC内のアベイラビリティゾーンごとに作成し、ネットワークアクセスを提供するエンドポイント
- アクセスポイント — アプリケーション固有のエントリーポイント(コンソール作成時は自動生成)
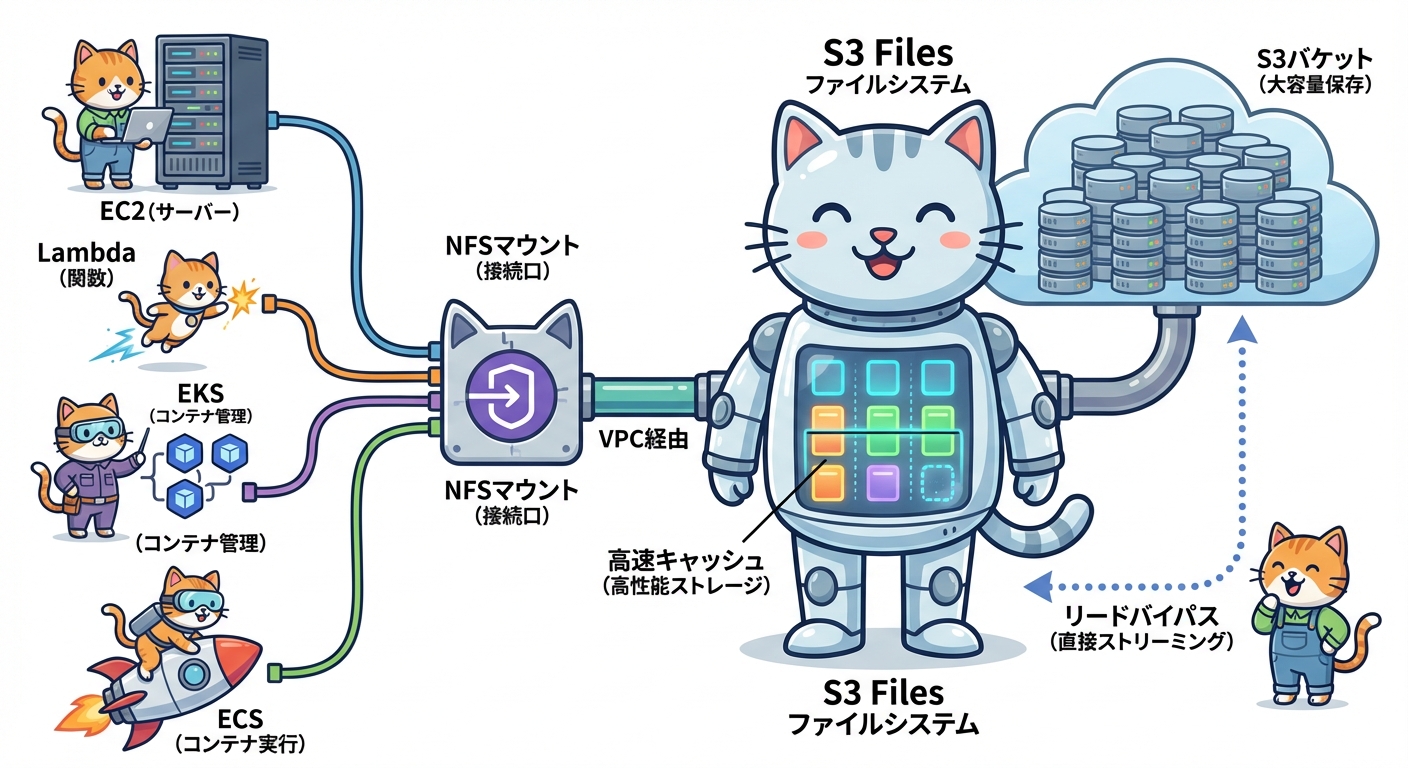
上図はS3 Filesのアーキテクチャ概念図です。EC2やLambdaなどのコンピューティングリソースは、マウントターゲット経由でファイルシステムにNFSアクセスします。アクティブなデータは高性能ストレージにキャッシュされ、大容量読み取り時はS3から直接ストリーミングされます。
S3 Filesが活きる主なユースケース
S3 Filesが特に価値を発揮するシナリオを具体的に見ていきましょう。
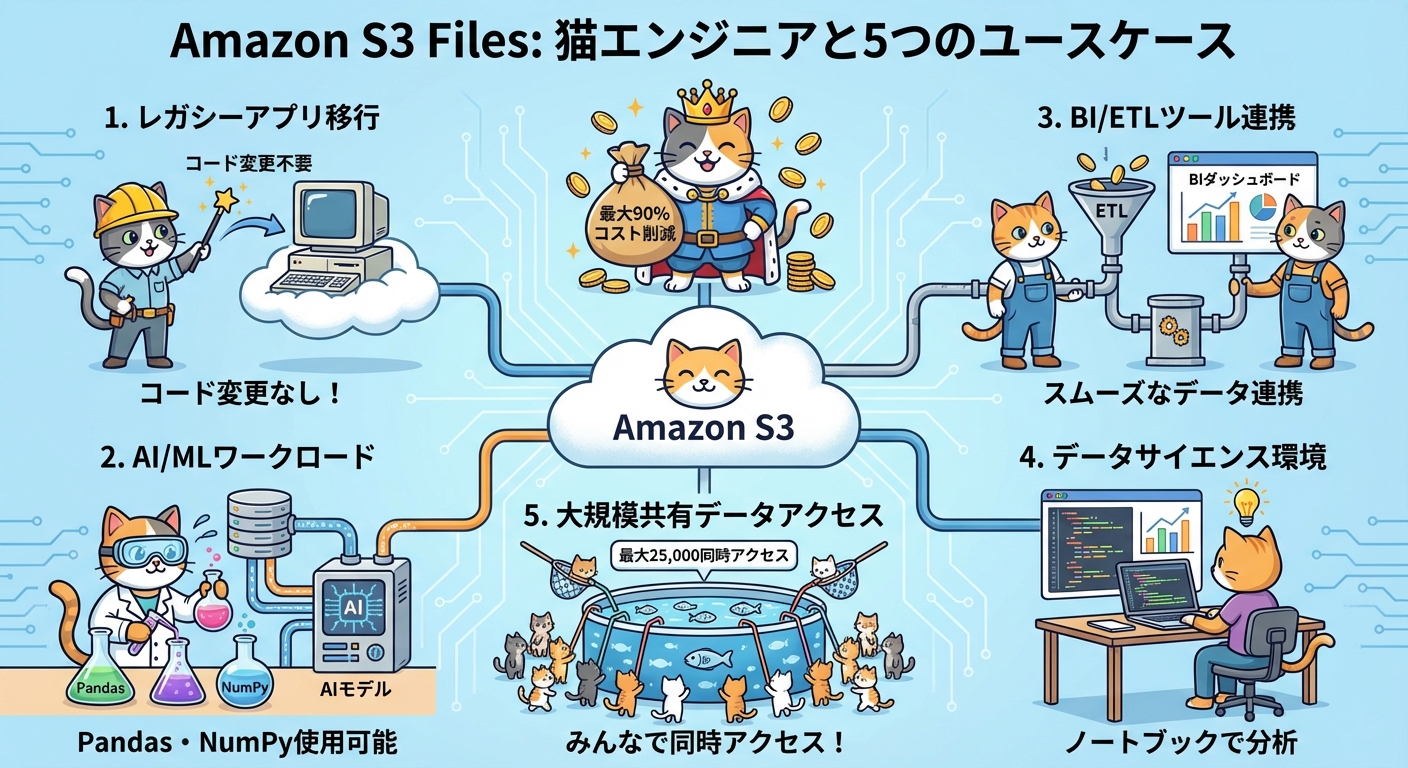
1. レガシーアプリのクラウド移行
ファイルシステムを前提とした既存アプリをS3に移行する際、従来はコードの大幅改修が必要でした。S3 Filesを使えば、ファイルパスベースのI/Oコードをそのまま流用でき、移行コストを削減できます。
2. AI/MLワークロードの効率化
PandasやNumPy、HuggingFaceなどのMLフレームワークはファイルシステムAPIで動作します。S3 Filesを使えば、S3上のデータをそのままトレーニングコードで利用でき、AIエージェントのネイティブなファイルシステムワークスペースとしても機能します。
3. BI/ETLツール連携
BIツールやETLフレームワークはファイルシステムパスを入力として受け取ることが多くあります。S3 Filesによりこれらのツールが直接S3データを参照でき、データパイプライン構築が簡略化されます。
4. データサイエンスとノートブック環境
Jupyter NotebookやPythonスクリプトから標準ファイル操作でS3データにアクセスでき、S3 SDKを使う必要がなくなります。
5. 大規模な共有データへの同時アクセス
最大25,000のコンピューティングリソース(EC2、Lambda、EKS、ECS、Batch)が同一のS3ファイルシステムを同時にマウントして読み書きできます。
料金体系と注意すべき制限事項
S3 Filesを本番運用で使う前に、料金と制限事項をしっかり理解しておくことが重要です。
料金の仕組み
S3 Filesの料金は主に3つの要素で構成されます。
1. ストレージ料金
高性能ストレージ上に存在するアクティブデータのサイズに対して課金されます。アクティブでないデータは保持期間(デフォルト30日)を過ぎると自動削除されるため、実際に使用中のデータに対してのみ課金されます。
2. ファイルシステムアクセス料金
ファイルシステムの高性能ストレージに対する読み書き操作に課金されます。ただし、1MB以上の大きなファイルについては、S3から直接ストリーミングされるためS3 Filesのアクセス料金は発生せず、標準のS3 GET料金のみとなります。
3. S3 GETリクエスト料金
リードバイパスによってS3から直接読み取る際の標準S3料金です。
AWSはS3 Filesを使うことで、「S3と別のファイルシステム間でデータを移送するコストと比べて最大90%のコスト削減が可能」としています。データを二重に持たずにS3を信頼できる唯一のデータソースとして扱えるためです。
注意すべき制限事項
ファイルロックとS3 APIの整合性
NFS v4.2のファイルロックはサポートされていますが、S3 API経由で行われた変更はロック機構を迂回します。ファイルシステム経由とS3 API経由の両方から同じデータを更新するような混在ワークロードでは、アプリケーションレベルで同時実行制御が必要です。
競合時のデータ処理
ファイルシステムとS3バケットの両方で同じファイルが変更された場合、S3バケット側の変更が優先されます。ファイルシステム側の変更は`.s3files-lost+found`ディレクトリに退避されます。この挙動を事前に把握したうえで、書き込みワークフローを設計する必要があります。
バージョニングの必須化
S3 Filesを使用するには、連携するS3バケットでバージョニングを有効化する必要があります。既存のバケットを利用する場合は設定変更が必要です。
同期レイテンシー
ファイルシステムからS3への同期には約63〜66秒程度のレイテンシーが発生します。リアルタイム性が求められるユースケースでは注意が必要です。
マウントターゲットの制約
マウントターゲットは1アベイラビリティゾーンにつき1つまでです。マルチAZ構成のアプリケーションでは、各AZに個別のマウントターゲットを作成する必要があります。
S3 Filesの利用開始手順
実際にS3 Filesをセットアップする手順を解説します。AWSマネジメントコンソールとAWS CLIの両方で設定が可能です。
前提条件
- AWS CLI 2.34以上がインストールされていること
- amazon-efs-utils 3.0.0以上がマウントするEC2インスタンスにインストールされていること
- 対象S3バケットでバージョニングが有効化されていること
- 適切なIAM権限が設定されていること(s3:ListBucket、s3:GetObject*、s3:PutObject*など)
CLIでの設定手順
CLIを使う場合、ファイルシステム作成とマウントターゲット作成の2ステップが必要です。コンソールでは「Files」タブから「ファイルシステムを作成」ボタンをクリックするだけで自動作成できます。
Step 1 — ファイルシステムの作成
aws s3files create-file-system \
--region us-west-2 \
--bucket arn:aws:s3:::your-bucket-name \
--role-arn arn:aws:iam::123456789012:role/S3FilesRoleStep 2 — マウントターゲットの作成
aws s3files create-mount-target \
--region us-west-2 \
--file-system-id fs-0aa860d05df9afdfe \
--subnet-id subnet-0abc12345def67890Step 3 — EC2インスタンスへのマウント
sudo mkdir /home/ec2-user/s3files
sudo mount -t s3files fs-0aa860d05df9afdfe:/ /home/ec2-user/s3filesマウント後は通常のLinuxファイルシステムと同様に`ls`や`cp`、Pythonの`open()`などが使用可能です。AWS Lambda、Amazon EKS、Amazon ECSのFargateタスクからも利用できます。
EFSとの比較とS3 Filesを選ぶ判断基準
S3 FilesはAmazon EFSをベースに構築されているため、使い分けの判断基準を整理しておきましょう。
Classmethod社の検証では、1GBファイルの書き込みスループットはS3 Filesが約239MB/s、EFSが約242MB/sとほぼ同等でした。一方、小さなファイル(1KB×1,000件)ではEFSが約24%高速です。
S3 Filesを選ぶべきケースはすでにS3にデータが存在してファイルシステムアクセスを追加したい場合、S3 APIとファイルシステムの両方からデータにアクセスするワークロード、S3の高耐久性(11ナイン)を維持しながらファイルシステムUIを使いたい場合です。
EFSを選ぶべきケースは小さなファイルへのランダムアクセスが多くレイテンシーを最優先する場合、S3との連携が不要な純粋なNFSファイルシステムが必要な場合です。
Amazon S3 Filesは、S3に新たなアクセス手段を加えることで、既存アプリの移行コスト削減やMLワークロードの効率化、BI/ETLツール連携など幅広い場面で活用できます。S3利用者であれば特に移行コスト削減の観点から、導入を検討する価値が十分あります。S3 APIとの混在書き込みを行う場合はロック整合性に注意しながら、AWS公式ドキュメントのチュートリアルからぜひ試してみてください。
























