


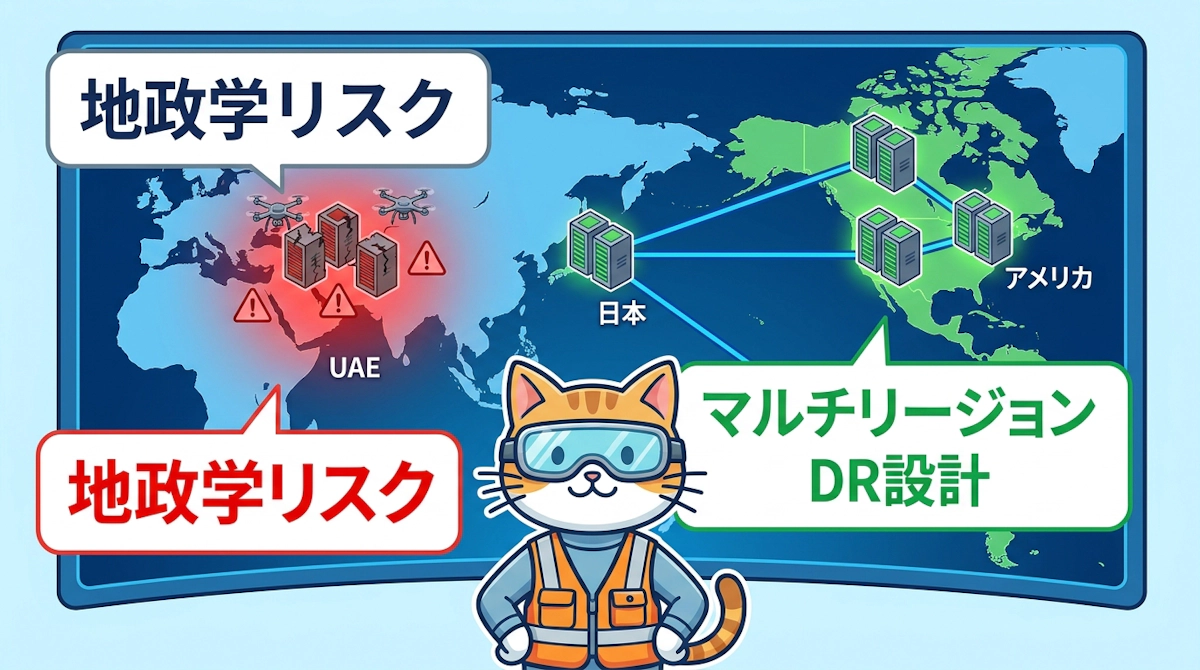
2026年4月30日、AWSはUAEリージョン(ME-CENTRAL-1)が深刻な物理的被害を受け、復旧に数カ月を要する見込みであることを公式に発表しました。ドローン攻撃に起因するこの事態は、クラウドインフラの可用性設計に対する従来の常識を根本から問い直す出来事です。今回は、インシデントの概要を整理したうえで、地政学リスクとクラウド冗長性設計について考えます。
何が起きたのか ─ AWSのUAEリージョンに発生したインシデント
2026年3月、中東情勢が急激に悪化しました。米国とイスラエルによるイランへの軍事行動に端を発した紛争のなかで、イランによるドローン攻撃がAWSのUAEリージョン(ME-CENTRAL-1)の物理的なデータセンター施設を直撃したと報じられています。
被害の規模は甚大でした。ME-CENTRAL-1では、3つのアベイラビリティゾーン(AZ)のうち2つが著しい機能障害に陥りました。バーレーンリージョン(ME-SOUTH-1)でも、施設近辺でドローン攻撃が発生し、影響が波及しました。
AWSはインシデント発生から約2カ月後となる2026年4月30日に状況報告を発表し、次のように述べています。
このプロセスには数か月かかる見込みです。
また、請求業務(billing)は一時停止されており、AWSはユーザーに対して「すべてのアクセス可能なリソースを他のリージョンへ移行」することを強く推奨しています。現在AWSが中東で展開するリージョンはバーレーン・UAE・イスラエルの3つですが、いずれも今回の紛争影響圏に近い場所に位置しています。
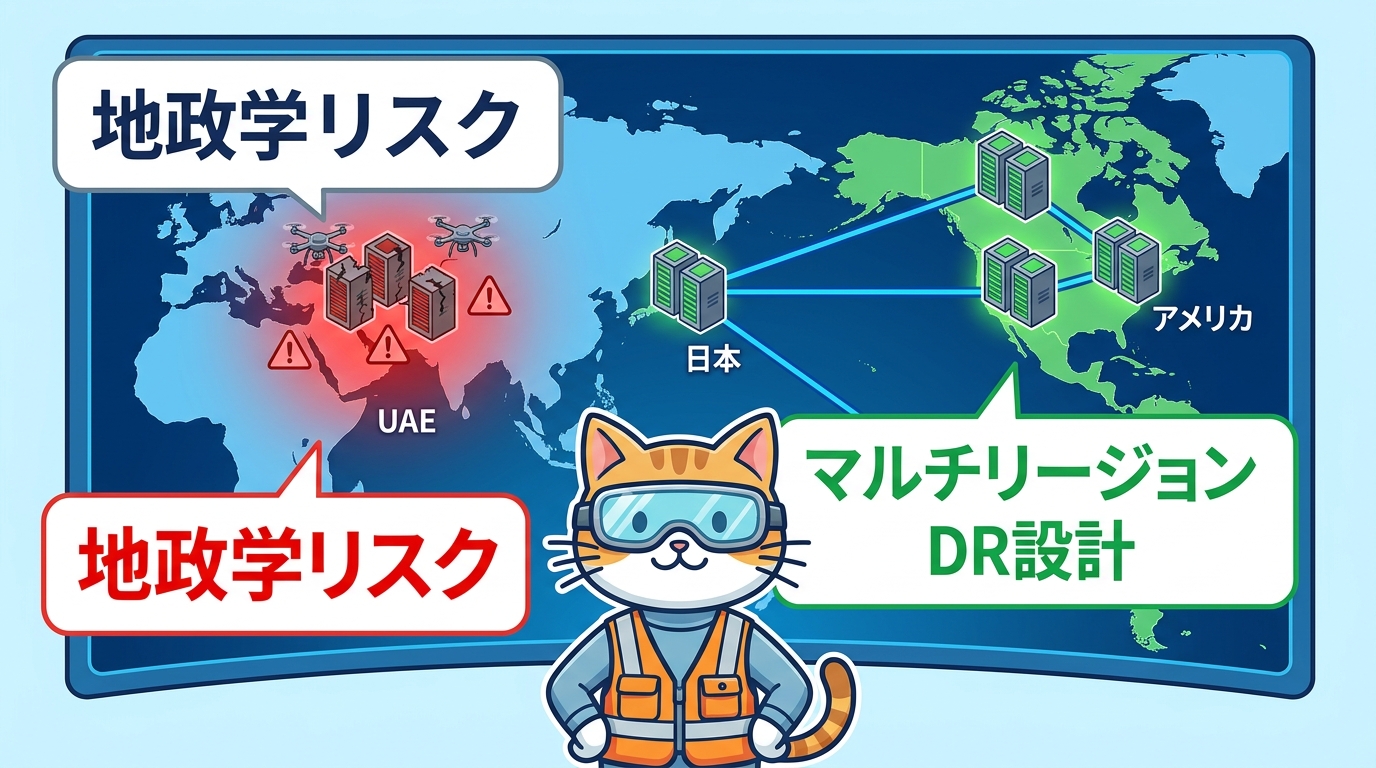
クラウドインフラは地政学リスクから切り離せない
今回のインシデントは、クラウドインフラに対するある種の「神話」を崩す出来事でした。それは「クラウドは物理的な制約から解放されている」という思い込みです。
クラウドは確かに、ハードウェアの管理やデータセンター運用の煩わしさから利用者を解放します。しかし、クラウドプロバイダーのデータセンター施設そのものは、現実世界の特定の場所に物理的に存在しています。電力・冷却・ネットワーク回線・建屋 ─ これらはすべて現地の物理的条件に依存しています。
ソフトウェア障害やハードウェア障害であれば、マネージドサービスの冗長化やオートスケーリングによって迅速な回復が期待できます。しかし今回のように物理インフラが直接的な損傷を受けた場合、「数カ月」という復旧期間は現実的な見通しです。ソフトウェアの再起動や設定変更では対処できません。
また、地理的に近接した複数リージョンを選択することで「マルチリージョン構成にしている」と考えるのも危険な発想です。バーレーンとUAEは互いに数百キロしか離れておらず、同一の地政学的リスクにさらされる可能性があります。今回まさにその懸念が現実のものとなりました。
地政学リスクは、自然災害リスクや技術的障害リスクと並ぶ、インフラ設計上の重要な考慮要素です。「特定地域の政治情勢が悪化したとき、システムはどうなるか」という問いを、アーキテクチャ設計の初期段階から持つ必要があります。
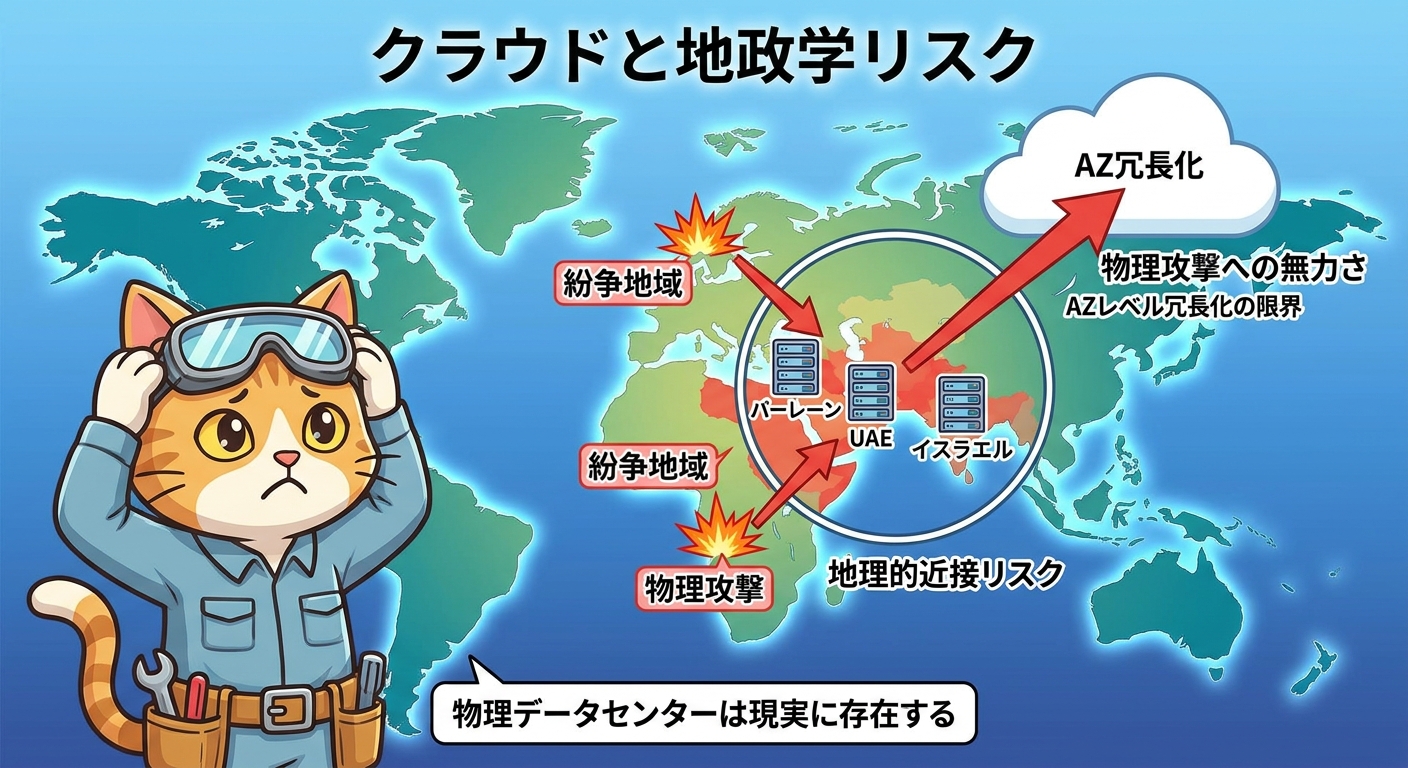
AWSのリージョン・AZ設計を理解する
マルチリージョン設計の前提として、AWSのインフラ構造を整理しておきます。
リージョンとは、地理的に独立したクラウド提供拠点です。2026年現在、AWSは世界30以上のリージョンを展開しており、各リージョンは独立したネットワーク接続を持ちます。
アベイラビリティゾーン(AZ)は、各リージョン内に複数(通常2〜6個)設置された独立した物理データセンタークラスターです。電力・ネットワーク・冷却システムが互いに独立しており、1つのAZで障害が発生しても他のAZが継続稼働できるよう設計されています。
Regional Services(Amazon S3、Amazon DynamoDBなど)は、1リージョン内の複数AZにわたってデータを自動的にレプリケーションし、高可用性を実現しています。これにより、単一のAZ障害に対しては高い耐性を持ちます。
今回のインシデントが示したのは、AZ分離設計が想定する「インフラ間の独立性」が、外部からの物理的攻撃に対しては十分でないケースがあるということです。3つのAZが地理的に近接しているため、ドローンや砲撃といった攻撃の影響範囲が複数AZを同時に覆うことがあり得ます。AZレベルの冗長化は、自然災害・ハードウェア障害・電源障害といった想定シナリオには有効ですが、大規模な物理的破壊に対しては限界があります。
マルチリージョン・ディザスタリカバリ設計のベストプラクティス
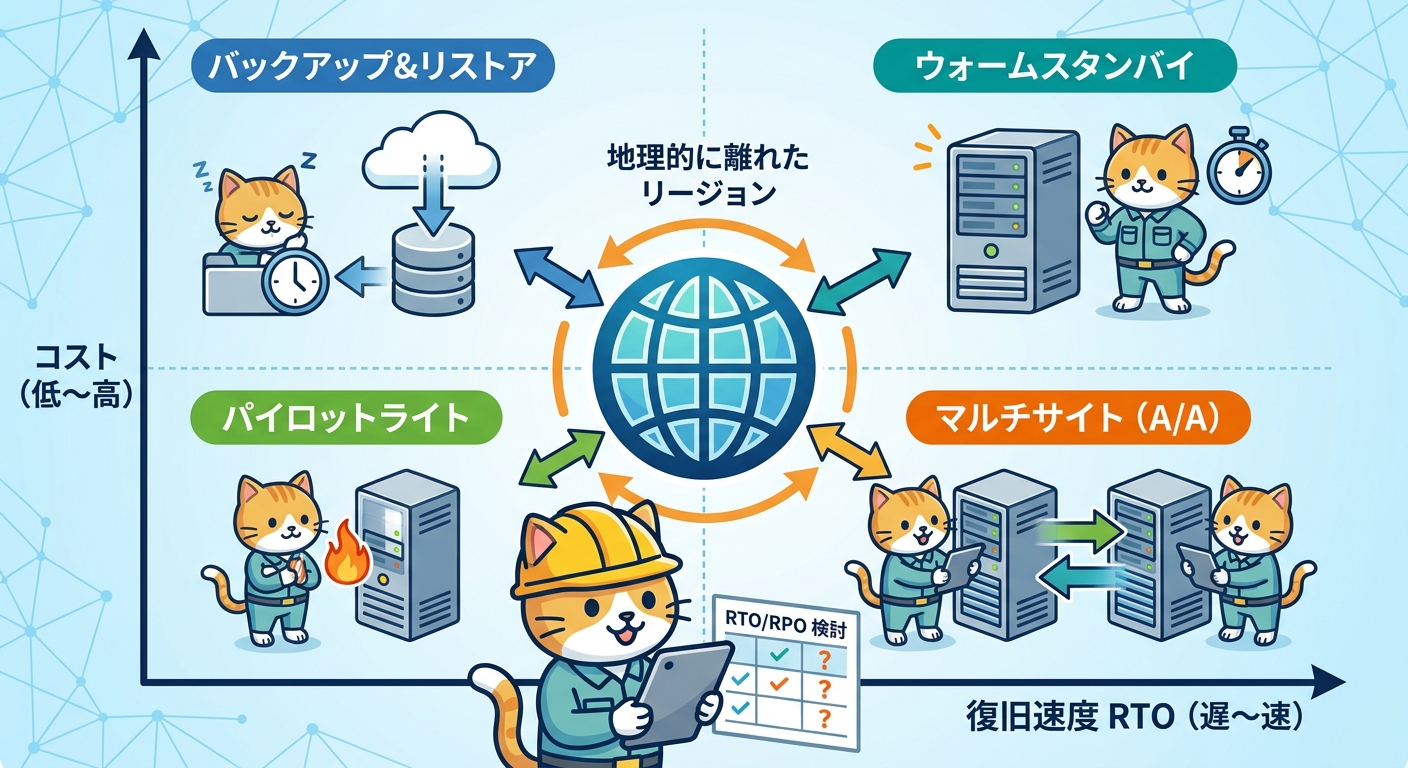
地政学リスクを含む広範なリスクに対応するためには、マルチリージョン構成によるディザスタリカバリ(DR)設計が不可欠です。AWSが公式に定義する4つの戦略を紹介します。
バックアップ&リストアは最もシンプルなアプローチです。データのバックアップを定期的に別リージョンへ保存し、災害時にリストアします。RTO(目標復旧時間)は24時間以上になることが多く、RPO(目標復旧時点)も数時間〜1日程度です。コストは最も低いですが、復旧までの停止時間が長くなります。
パイロットライトは、最小限のコアコンポーネントのみをセカンダリリージョンで常時稼働させておく戦略です。障害発生時に残りのリソースを起動してフルスケールで稼働させます。RTOは数時間程度まで短縮できます。
ウォームスタンバイは、縮小版の本番環境をセカンダリリージョンで常時稼働させておく手法です。障害発生時にスケールアップして引き継ぎます。RTOは数十分程度まで短縮でき、コストと復旧速度のバランスが取れた現実的な選択肢です。
マルチサイト(アクティブ/アクティブ)は、複数リージョンで同時に本番稼働する最高の可用性を実現する構成です。RTOとRPOはほぼゼロに近づきますが、コストは最も高くなります。ミッションクリティカルなシステムに適しています。
いずれの戦略においても、以下の実装要素が重要です。
- 地政学的距離を考慮したリージョン選択: セカンダリリージョンは、プライマリリージョンと同一の地政学的リスク圏を避けて選択する。例えば中東系システムであれば、東京・シンガポール・フランクフルトなど地理的に離れたリージョンを候補とする。
- クロスリージョンデータレプリケーション: Amazon S3 Cross-Region Replication、Amazon DynamoDB Global Tables、Amazon RDS Cross-Region Read Replicasなどのマネージドサービスを活用し、データの同期を自動化する。
- Route 53ヘルスチェック+フェイルオーバー: DNSレベルでのトラフィック切り替えを自動化し、プライマリリージョンの障害を検知したときにセカンダリへ切り替わるように設定する。
- IaC(Infrastructure as Code)の徹底: AWS CloudFormationやTerraformでインフラをコード化し、セカンダリリージョンでも同一環境を再現できる状態を常に維持する。
今回のインシデントから得られる設計上の教訓
今回のAWS UAE リージョンのインシデントは、単なる「可用性の問題」ではありません。クラウド利用者が普段あまり意識しない「物理インフラの地政学リスク」が、実際のシステム停止として顕在化した事例です。
このインシデントを踏まえ、システム設計者・インフラ担当者として見直すべきポイントをまとめます。
まず、現在のアーキテクチャが地政学リスクを考慮しているかを確認してください。「マルチリージョン構成にしている」と認識していても、選択したリージョンが地政学的に近接している場合、今回のような広域被害には対応できない可能性があります。
次に、定期的なDR訓練の実施を推奨します。フェイルオーバーのプロセスは、設計書に書いてあるだけでは信頼できません。実際に別リージョンへの切り替えを演習し、RTOとRPOが設計通りに実現できるか検証することが重要です。
また、IaCによる環境再現性の担保も欠かせません。手動で構築された環境はリカバリ時に再現が難しく、障害対応の工数を大幅に増加させます。すべてのインフラをコード化しておくことで、セカンダリリージョンでの環境再構築を迅速に行えます。
Ragateでは、認定を持つ専門チームが、お客様のシステム要件・リスク許容度・コスト制約に応じたクラウドアーキテクチャ設計を支援しています。今回のインシデントを機に、自社のDR設計を見直したいとお考えの方は、ぜひお問い合わせください。
























