



NVIDIA Nemotron 3 Nano Omniとは
NVIDIAは2026年4月28日、オープンソースのマルチモーダルAIモデル「Nemotron 3 Nano Omni」を公開しました。映像・音声・テキスト・画像のすべてを単一モデルで処理できる「オムニモーダル」設計を採用し、エンタープライズグレードのAIエージェント開発に必要な機能を一枚のモデルに集約しています。
最大の特徴は、総パラメータ数30Bでありながら推論時には3Bのみを有効化するMoE(Mixture-of-Experts)アーキテクチャを採用している点です。これにより、大規模モデルに匹敵する表現力と、軽量モデル並みの推論効率を同時に実現しています。
モデルの全重みはHugging Faceで公開されており、BF16(フル精度)・FP8・NVFP4の各フォーマットで取得できます。コミュニティによるGGUG版も提供されており、研究者から実用開発者まで幅広いユーザーが利用できる環境が整っています。コンテキスト長は131,072トークン(約131K)に対応しており、複数ドキュメントを横断した長文処理や長尺動画の理解にも力を発揮します。
NVIDIAの公式アナウンスによると、同モデルは6つの公開リーダーボードでトップスコアを記録しており、複雑なドキュメントインテリジェンスや動画・音声理解において業界最前線の精度を達成しています。
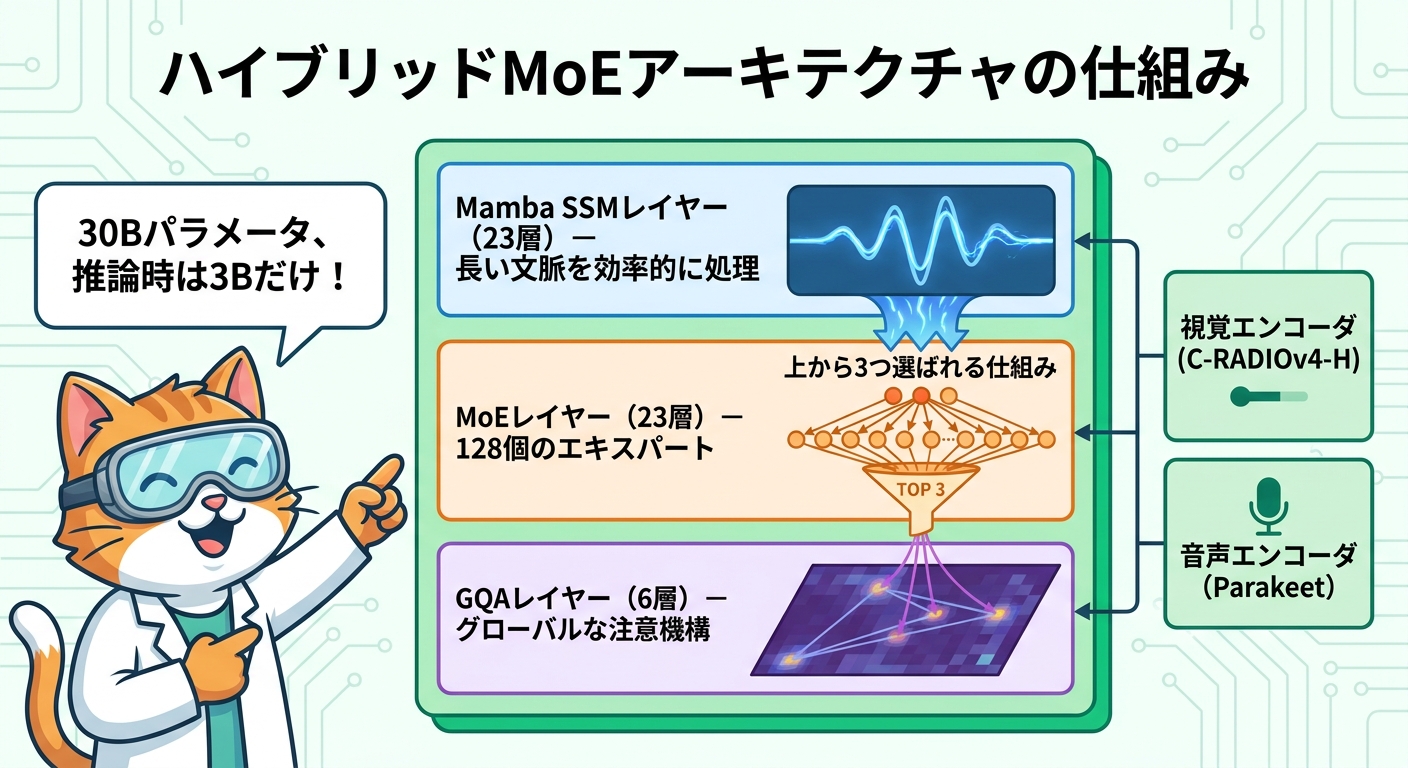
ハイブリッドMoEアーキテクチャの仕組み
Nemotron 3 Nano Omniは、3種類のニューラルネットワーク構造を組み合わせた「ハイブリッドMamba-Transformer MoE」を採用しています。このアーキテクチャが、軽量かつ高性能を実現する核心です。
言語バックボーンとなるNemotron 3 Nano 30B-A3Bは、以下の3種のレイヤーを組み合わせて構成されています。
- Mamba SSMレイヤー(23層):選択的状態空間モデル(Selective State-Space Model)による効率的な長文脈処理。Transformerのような二乗オーダーの計算コストを回避しながら、長大なシーケンスを扱えます。
- MoEレイヤー(23層):128個のエキスパートネットワークを保持し、各トークンに対してtop-6ルーティングで最適なエキスパートを選択します。共有エキスパートも配置されており、汎用的な処理能力を維持しています。
- GQAレイヤー(6層):Grouped-Query Attentionによるグローバルな表現力の保持。Mambaとの組み合わせにより、局所的・大局的な文脈理解を両立します。
マルチモーダルの入力処理は、2つの専用エンコーダが担います。視覚情報には「C-RADIOv4-H」を使用し、画像・動画フレームを高精度にエンコードします。音声情報には「Parakeet-TDT-0.6B-v2」を使用し、多様なスピーカーやアクセント、背景ノイズが混在する長尺音声にも対応します。エンコードされた各モダリティの情報は言語バックボーンに渡され、テキストと統合した推論が行われます。
この設計により、従来は視覚・音声・テキストの各専門モデルを組み合わせて構築していたマルチモーダルパイプラインを、1つのモデルだけで完結させることが可能になりました。スタックの複雑さが大幅に軽減され、レイテンシ削減・コスト最適化・デバッグの簡易化につながります。
ベンチマークと性能指標
Nemotron 3 Nano Omniは、同等クラスのオープンソースマルチモーダルモデルと比較して際立ったスループット優位性を示しています。NVIDIAの公開データによると、マルチドキュメント用途では同等モデルの7.4倍、動画用途では9.2倍の高スループットを実現しています。
この優位性の背景には、MoEアーキテクチャによる「推論時に活性化するパラメータを3Bに絞る」設計があります。30Bの全パラメータを毎回計算する密なモデルとは異なり、各推論ステップで必要なエキスパートのみを呼び出すため、計算効率が飛躍的に向上します。
ベンチマーク上の主な性能指標は以下のとおりです。
- コンテキスト長:131,072トークン(長文書・長尺動画対応)
- リーダーボード:ドキュメントインテリジェンス・動画・音声理解の6つの公開ベンチマークでトップ
- マルチドキュメントスループット:同等オープンモデル比7.4倍
- 動画スループット:同等オープンモデル比9.2倍
また、Chain of Thought推論・ツールコーリング・JSON出力・単語レベルのタイムスタンプ付き文字起こしなど、エージェント開発に必要な実用機能も標準サポートしています。精度と速度を両立したこの性能は、高コスト・高レイテンシで敬遠されがちだったマルチモーダルAIの商用導入障壁を大きく下げる可能性を持ちます。

エンタープライズユースケースと活用事例
Nemotron 3 Nano Omniは、以下の4つのエンタープライズユースケースカテゴリに特化して設計されています。
ドキュメントインテリジェンス
契約書・SOW・MSA(マスタサービス契約)・財務文書・科学論文など、テキストと図表が混在する複雑な文書の解析を得意とします。OCR処理と自然言語推論を統合した一連の処理が単一モデルで完結するため、複数ツールを繋いだ従来パイプラインに比べて大幅にシステムを簡素化できます。法務・コンプライアンス・財務分析などの高付加価値業務への応用が期待されます。
動画・メディアインテリジェンス
長尺動画の内容理解・要約・質疑応答に対応します。映像と音声を別々に処理して後から統合する従来アプローチとは異なり、Nemotron 3 Nano Omniは音声・映像を単一の推論ストリームで処理します。メディア・エンターテインメント分野の映像分析、監視映像の自動解析、会議録画の要約・アクションアイテム抽出などに活用できます。
音声理解
Parakeet-TDT-0.6B-v2エンコーダの採用により、多様なスピーカー・アクセント・背景ノイズが混在する長尺音声の高精度な文字起こしを実現します。単語レベルのタイムスタンプが出力されるため、コールセンター音声分析・インタビュー記録・講演録の作成など幅広い用途で活用できます。
GUIコンピュータ使用エージェント
ブラウザ・アプリケーションのGUI操作を自動化するエージェントとして機能します。インシデント管理ダッシュボードの操作・メールワークフロー自動化・アジェンティックウェブ検索など、ソフトウェアを横断する作業の自動化に適しています。視覚的なUI理解とテキスト推論を組み合わせることで、RPA(Robotic Process Automation)の次世代版として位置づけることができます。
エッジAIへの展開方法
Nemotron 3 Nano Omniの大きな特徴のひとつが、エッジ環境での動作可能性です。4bit量子化を適用することで約25GBのRAMで動作し、以下の環境に対応しています。
- NVIDIA RTX 4090 / RTX Pro(VRAM 24GB以上)
- Apple M3/M4 Max(ユニファイドメモリ)
- シングルGPUクラウドインスタンス
対応GPU世代はAmpere・Hopper・Blackwellの3世代にわたり、既存のGPUインフラを活用した導入が可能です。
vLLMによる高スループット推論
vLLMはNemotron 3 Nano Omniに対して連続バッチング・ストリーミング推論をサポートしており、リクエストが集中するAPIサービスに適した構成です。vLLM公式ブログではNemotron Omni向けのクックブックが公開されており、すぐに試せるサンプルコードが提供されています。
NVIDIA TensorRT-LLMによる本番導入
低レイテンシが求められる本番環境では、NVIDIA TensorRT-LLMが推奨です。MoEカーネルの最適化(latent MoEカーネル)により、バッチ推論でのスループットと単一リクエストのレイテンシの双方を最小化します。
NVIDIA NIMマイクロサービス
NVIDIAが提供するNIM(NVIDIA Inference Microservice)を利用すると、コンテナイメージを取得してそのまま本番利用できます。APIエンドポイントを通じて他のサービスと統合しやすく、MLOpsパイプラインへの組み込みも容易です。
Amazon SageMaker JumpStart
AWSを利用しているユーザーは、Amazon SageMaker JumpStartからNemotron 3 Nano Omniを直接デプロイできます。マネージドインフラ上でエンドポイントを構築し、既存のAWSサービスと組み合わせたアーキテクチャをすぐに実現できます。
これらの複数の導入経路が整備されていることは、企業がPoC(概念実証)から本番環境への移行をスムーズに行えることを意味します。クラウド上の大規模APIサービスからオンプレミスのエッジデバイスまで、同一のモデルを様々な展開戦略で活用できる柔軟性がNemotron 3 Nano Omniの最大の強みのひとつと言えるでしょう。
オープンソースであることも重要な要素です。モデルの全重みにアクセスできるため、特定ドメインへのファインチューニングや、社内データを使ったカスタマイズが可能です。商用利用においても独自の価値を付加しやすく、AIエージェント製品を開発する企業にとって魅力的な選択肢となっています。
NVIDIAがハードウェアだけでなくオープンなAIモデルの分野でも存在感を強めるなか、Nemotron 3 Nano OmniはエッジからクラウドまでをカバーするマルチモーダルAIの新しい基準を示しています。エンタープライズAIエージェントの構築に取り組む開発者・研究者にとって、注目せずにはいられないモデルと言えるでしょう。









.webp?q=65&fm=webp&w=400&h=260&fit=crop)














