


生成AIの社内活用が「PoC止まり」から「全社内製化」へ踏み出そうとする段階で、必ず立ちはだかる二つの壁があります。一つは機密データを外部APIに渡せないというセキュリティの壁、もう一つは回答が事実と異なって返るハルシネーションの壁です。Ragate株式会社が情報システム部門・DX推進室の担当者506名を対象に行った調査では、生成AI活用における懸念事項として「セキュリティ懸念」が42.2%、「ハルシネーション懸念」が35.2%と上位を占めました。本記事では、Ragate代表の益子竜与志による書籍「AI駆動で進める小さく確実なクラウドネイティブ移行」(2026年3月19日 技術評論社刊、全512ページ)で提唱されているアプローチを踏まえ、Dify と Amazon Bedrock を組み合わせてセキュアな社内RAG基盤を内製化するための実装方針を、エンジニア視点で整理します。
なぜいま社内RAG基盤の内製化が経営課題になっているのか
日本企業のDX着手率は2021年の56%から2024年には73%まで上昇しましたが、実際に成果が出ている企業は28%にとどまっています。一方で、日本のAIシステム市場は2024年に1兆3,412億円と前年比56.5%で急成長し、2029年には4兆1,873億円へ拡大すると予測されています。市場が急拡大する裏で成果が伴わない構造的な理由は、生成AIを汎用SaaSのチャット画面で個人利用するに留め、社内データと結びつけて業務プロセスに組み込むところまで届いていないことにあります。
社内データと結びつけて初めて、生成AIは社員一人ひとりの「自分の業務」を理解した相談相手になります。そのための基盤がRAG(Retrieval-Augmented Generation)です。社内文書をベクトル検索で引き当てて、その内容を根拠としてLLMに回答させる仕組みにより、機密データを外に出さずに精度の高い回答を返せます。RAG基盤の内製化は、もはやIT部門の選択肢ではなく、AIの恩恵を全社で取りこぼさないための前提条件になりつつあります。
Dify と Amazon Bedrock が解消する2大ボトルネック
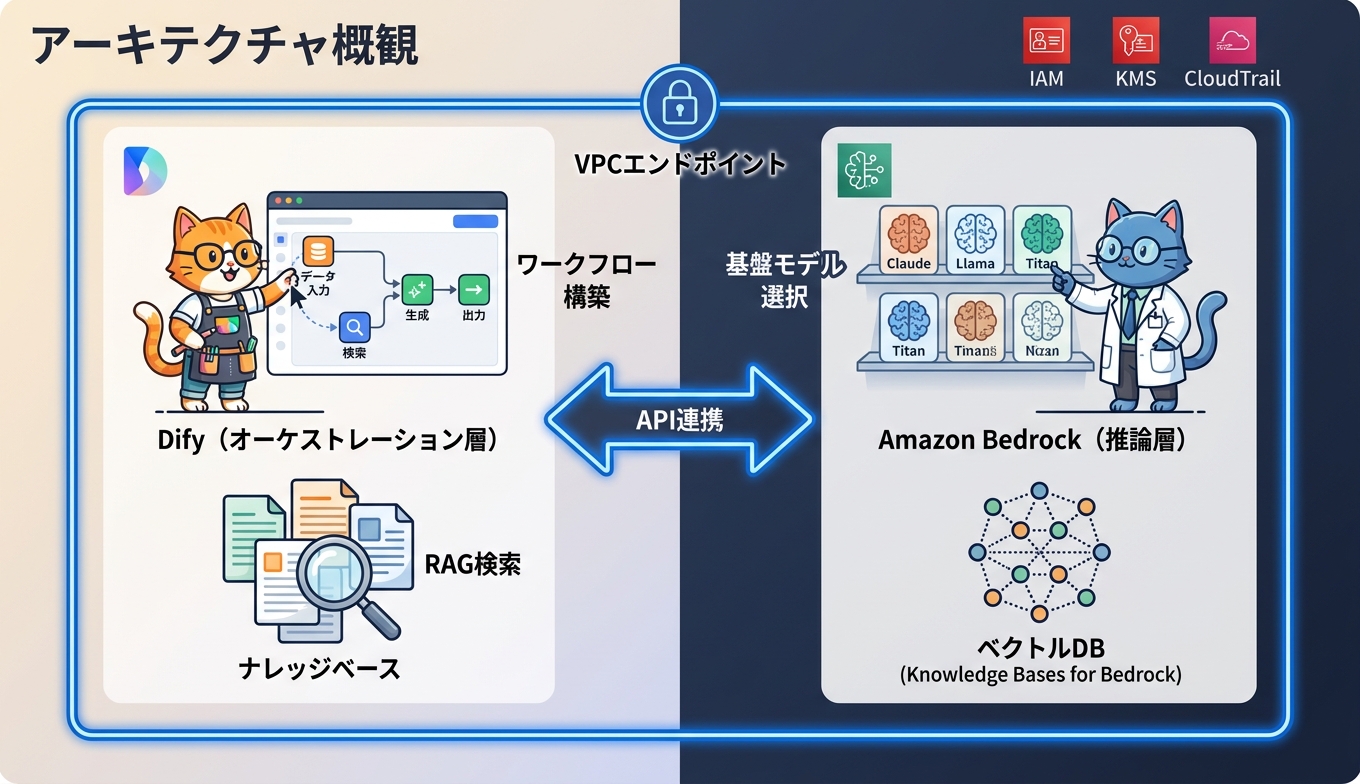
Dify はオープンソースのLLMアプリケーション開発プラットフォームで、ワークフローやエージェントをGUIで設計し、ナレッジベース連携やプロンプト管理、API公開までを一気通貫でカバーします。Amazon Bedrock は Anthropic Claude、Meta Llama、Mistral など主要な基盤モデルを単一APIで提供するAWSのフルマネージドサービスで、推論データの学習利用は行わない契約モデルで運用されます。両者を組み合わせることで、Dify の開発生産性と Bedrock のエンタープライズグレードのセキュリティ・可用性を同時に手に入れられます。
セキュリティ面では、Dify を EC2 や ECS でVPC内に閉じてホスティングし、Bedrock への通信を VPC エンドポイント(AWS PrivateLink)経由に固定すれば、社内文書もプロンプトも応答も、一度もインターネットに出ない構成が組めます。ハルシネーション面では、Bedrock の Knowledge Bases と Dify のナレッジベースを使い分け、検索結果に根拠としてのソース文書を引用させることで、回答の信頼性を構造的に担保できます。
4フェーズで進める「小さく確実な」内製化ロードマップ
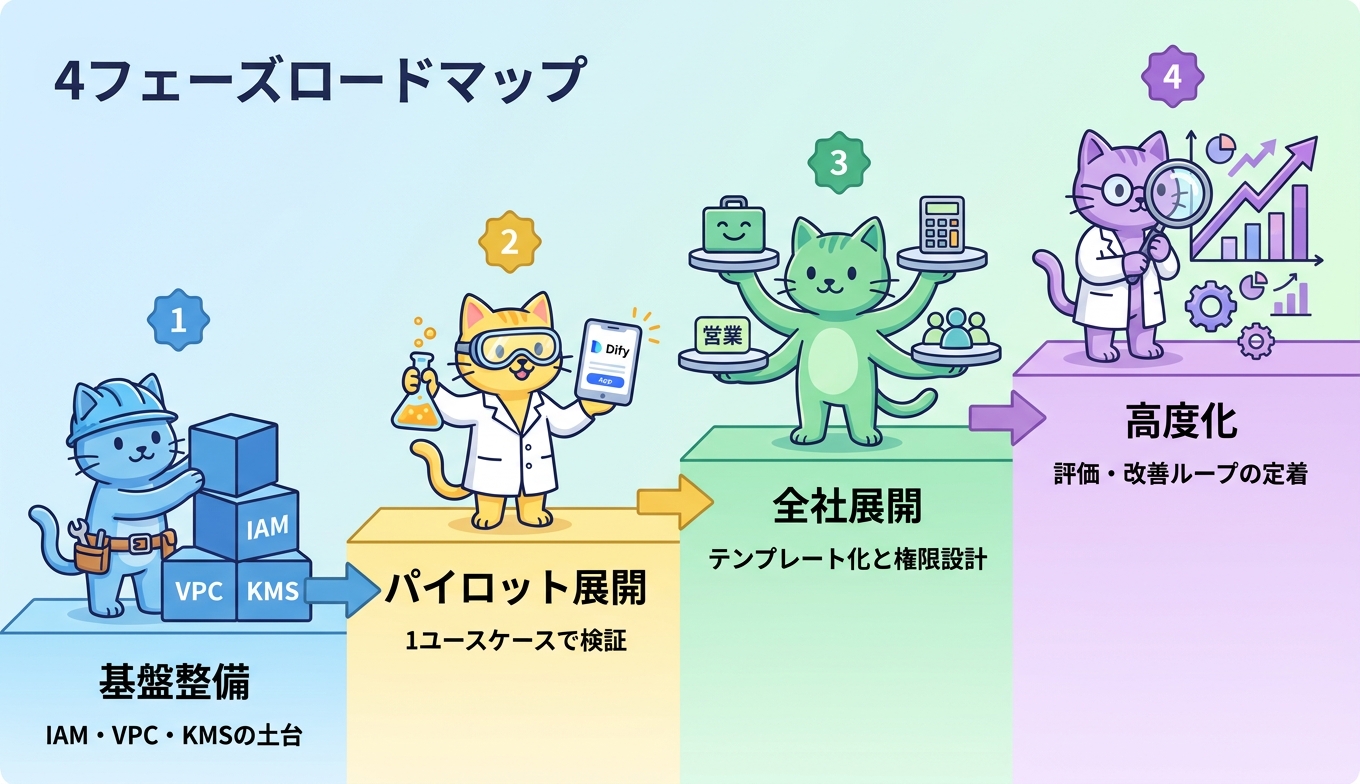
Ragate が官公庁システム更改や生成AI推進支援で適用してきたのが、「基盤整備、パイロット展開、全社展開、高度化」の4フェーズロードマップです。一気に全社展開を狙うのではなく、リスクと投資を段階的に積み上げる進め方で、AI駆動開発の落とし穴を回避します。
基盤整備フェーズでは、IAM ロール、VPC、KMS、ログ集約といったAWSの土台を先に固め、Bedrock のモデルアクセス権やナレッジベース用 S3 バケットの暗号化要件を満たしておきます。パイロットフェーズでは、ナレッジ検索や議事録要約といった成果が見えやすい1ユースケースを Dify で構築し、500時間規模の工数削減効果を定量的に測ります。全社展開フェーズでは、Dify アプリのテンプレート化と部門単位の権限分離を行い、利用者数の拡大に耐える設計へ整えます。高度化フェーズでは、評価データセットと回答品質メトリクスを整備し、プロンプトとモデルを継続改善するループを定着させます。
ハルシネーションを抑えるRAG実装の勘所
RAG はハルシネーション対策の最有力手段ですが、雑に組むと「もっともらしい誤答」を量産する逆効果な仕組みになります。実装で押さえるべき勘所は3点あります。第一に、ドキュメントのチャンク分割です。意味的にまとまった単位(見出し配下や段落単位)で200から800トークン程度に区切り、隣接チャンクとオーバーラップを持たせて文脈の断絶を防ぎます。第二に、検索結果の絞り込みです。ベクトル検索の上位件数を5から10件に絞り、関連スコアが閾値を下回るチャンクは渡さない設計にすることで、無関係な情報による幻覚を抑えます。
第三に、回答の根拠提示です。Dify のワークフロー上で、回答とともに参照したソース文書とページ番号を返すよう構成し、利用者が一次情報を確認できる導線を必ず設けます。Bedrock の Knowledge Bases は引用情報(citations)を API レスポンスに含めて返すため、フロント側はそれをそのまま表示するだけで根拠付き回答が実現できます。ハルシネーションをゼロにすることは原理的に不可能ですが、利用者が即座に検証できる状態を保つことで、誤答が業務判断に直結するリスクを大幅に下げられます。
あわせて、埋め込みモデルの選定とクエリの前処理も精度に大きく影響します。日本語社内文書を扱う場合は、英語に最適化されたモデルではなく日本語の語彙分布に合うモデルを選び、ユーザーの曖昧な質問はワークフロー内で一度LLMによるクエリリライトを挟むと、検索ヒット率が体感で向上します。Dify のワークフロー機能はこうした多段処理を視覚的に組めるため、検索チューニングのサイクルを高速に回せます。
内製化を定着させる組織と運用のポイント
技術選定が正しくても、組織と運用設計が伴わなければ「作ったが使われない基盤」になります。定着のためのポイントは三つです。一つ目は、Dify のアプリ作成権限を段階的に開放することです。最初は情報システム部門のみが作成し、テンプレート化が進んだ段階で各部門のキーパーソンに広げる順序にすると、品質と統制を両立できます。二つ目は、ナレッジベースの鮮度管理です。S3 への文書アップロードからベクトル化までを自動化し、社内ドキュメントの更新が遅延なく検索結果に反映される仕組みを整えます。
三つ目は、利用ログを軸とした継続改善です。Dify は会話ログとフィードバック(高評価・低評価)を蓄積でき、Bedrock の CloudWatch メトリクスと組み合わせれば、回答品質の悪化を早期に検知できます。Ragate の定額制テクノロジーアドバイザリーのように、外部の専門家を運用フェーズまで巻き込みながら、社内人材のリスキリングを並行して進める伴走型のアプローチは、内製化を「作って終わり」にしないための実効性の高い選択肢です。生成AIを業務インフラに昇格させる旅は、技術と組織の両輪を回し続ける長期戦であり、その第一歩として Dify と Amazon Bedrock の組み合わせは現時点で最もバランスの取れた解の一つだと言えます。
























