


Amazon Managed Workflows for Apache Airflow(以下、Amazon MWAA)を本番運用していると、必ず一度はぶつかる悩みがあります。「タスクがキューに溜まり始めたが、ワーカーを増やすべきなのか、それとも別の問題なのか」という判断です。多くの現場で、ワーカーを増設したのに改善せず、月額のコストだけが上がってしまったというケースが繰り返されています。本記事では、AWSが2026年5月に公開したガイド「A guide to Airflow worker pool optimization in Amazon MWAA」を踏まえ、Amazon MWAAのワーカースケーリングの仕組み、Airflow側のタスクプールと並列制御の階層、そしてワーカー増設の妥当性を判断するための実践フレームワークを、データエンジニアおよびMLOpsエンジニア向けに整理します。
「ワーカーを増やせば速くなる」は本当か
Apache Airflowに少しでも触れた経験があると、CeleryExecutor構成における「ワーカー追加によるスループット改善」は、定番のチューニング手段として頭に浮かびます。実際、Amazon MWAAも環境クラスを引き上げたり、最大ワーカー数を増やしたりすることで処理能力を伸ばせます。一方で、見かけ上の「遅さ」や「キュー詰まり」が、ワーカー不足ではなくAirflowの設定値、DAG設計、メタデータデータベース側のリソース消費に起因しているケースは非常に多く見られます。
このような場合、ワーカーを足しても改善しないどころか、稼働率の低いワーカーが大量に並ぶことになり、月額コストだけが膨らんでしまいます。Amazon MWAAのワーカープールを最適化するうえでまず必要なのは、ワーカー追加という打ち手を「使うべきか、使わないべきか」を切り分ける判断軸です。本記事ではその判断軸を、仕組み・構造・パターン・監視の順に積み上げて解説していきます。
Amazon MWAAにおけるワーカースケーリングの仕組み
Amazon MWAAでは、CeleryExecutorを採用したワーカー群が、メッセージキューを介してスケジューラーから受け取ったタスクを並列に処理します。各環境クラスには最小ワーカー数と最大ワーカー数が設定されており、Amazon MWAAはタスクの滞留状況に応じてその範囲内でワーカーをオートスケーリングします。
各ワーカーが同時に処理できるタスク数は、Airflowの設定 celery.worker_autoscale によって (max, min) 形式で制御されます。たとえばmw1.smallで最小4ワーカーがある場合、デフォルト設定では1ワーカーあたり5タスクなので、合計20タスクを同時に実行できます。20を超える同時実行が必要になったタイミングでオートスケーリングイベントが発生し、追加ワーカーがプロビジョニングされますが、起動には一定の時間がかかります。この立ち上がり時間の間にタスクは滞留し、キュー長が膨らんでいくため、増設だけで遅延を吸収しきれないことがあります。
環境クラスごとのデフォルトのワーカー同時実行数は、mw1.smallが5タスク、mw1.mediumが10タスクと、AWS公式ガイドに明記されています。ここで注意すべき重要なポイントが一つあります。Amazon MWAAは、環境クラスを変更してもワーカーの同時実行数を自動で更新しません。mw1.smallからmw1.mediumへアップグレードしても、Airflow設定で celery.worker_autoscale を明示的に書き換えない限り、1ワーカーあたりの処理能力は5タスクのまま据え置かれてしまいます。「環境クラスを上げたのに体感速度が変わらない」という相談の多くは、この設定取り残しが原因です。
TaskPoolとWorkerの関係と階層的な並列制御
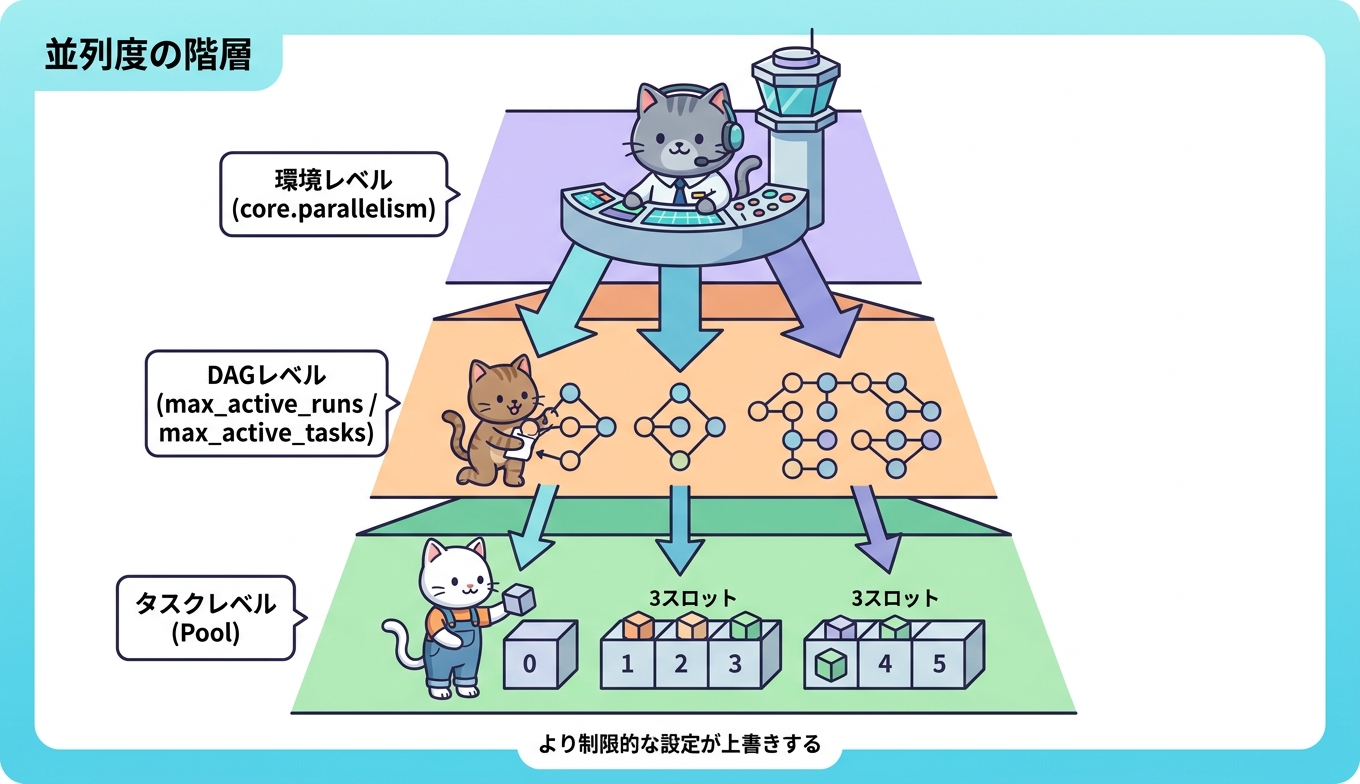
ワーカーを増やしても処理が伸びないもう一つの典型的な原因が、Airflow側に設定された並列制御の上限に当たっているケースです。Airflowはタスクの並列度を、環境レベル・DAGレベル・タスクレベルの3層で制御しており、これらは「より制限的な設定が、より許容的な設定を上書きする」という階層原則で動作します。
環境レベルでは、スケジューラーが管理できる最大タスク総数を core.parallelism で定めます。DAGレベルでは、DAG単位の同時実行数を max_active_runs、ひとつのDAG内で同時に走らせるタスク数を max_active_tasks で制限します。タスクレベルでは、Airflowのプール機能で「同時に何タスクまで通すか」をスロット数として定義します。たとえばスロット数3のプールに4つ目のタスクが投入されると、空きが出るまで実行待ちとなり、ワーカー側に余裕があってもアイドルのまま待機します。
ここで覚えておきたいのは、これらの設定はそれぞれが独立した「天井」を設けるということです。core.parallelism がいくら大きくても、対象のDAGに max_active_runs_per_dag=2 が指定されていれば、ワーカー容量に余裕があっても同時に2つのDAG実行までしか進みません。逆に、DAG側で制限していなくても、プールのスロット数が小さければそこで頭打ちになります。ワーカー増設の前に、まずこの階層のどこで制限がかかっているのかを把握することが、無駄な増設を避ける最初の一歩です。
あわせて、実行タイムアウトとリトライ設定も並列度に影響します。タイムアウト設定が緩いまま失敗タスクが滞留すると、そのタスクが長時間スロットを占有し、後続タスクが進めなくなります。タスクごとの想定実行時間を見直し、適切な execution_timeout を設定しておくことが、見えづらい詰まりを防ぐ地味ながら効果的な打ち手です。
ワーカー増設の判断フレームワーク(4パターン)

AWS公式ガイドは、Amazon MWAA運用で遭遇する典型的な遅延・滞留を4つのパターンに分類し、それぞれに対する推奨対応を整理しています。ここではそのパターンと、ワーカー増設が妥当かどうかの判断を実務的に解説します。
パターンA/ワーカーCPU使用率が高い。タスク自体がCPUを多く消費しているケースです。原因は、タスクの実装が最適化されていない、あるいはより小さな粒度に分割されていないことにあります。推奨対応は、まず水平スケーリング(ワーカー追加)、続いて垂直スケーリング(環境クラスのアップグレード)、最後にDAGおよびスケジューリングの最適化という順序です。一方で、CPU使用率が常に90%を超えるような状態が継続している場合は、単一タスクの設計を見直さない限り、ワーカーをいくら増やしてもキューの先頭にあるタスクが詰まり続けます。
パターンB/タスクのキュー待ち時間が長い。ワーカーは余裕があるにもかかわらず、タスクがキューで待たされているケースです。これはオートスケーリングのプロビジョニング遅延に起因することが多く、対策は celery.worker_autoscale のmax値を引き上げる、または最小ワーカー数自体を増やして立ち上がり遅延の影響を緩和することです。ここは比較的素直に「ワーカー追加」が効くシナリオです。
パターンC/スケジューリング遅延。新しいDAGを追加した結果、リソース競合が発生して既存DAGの実行開始時刻にばらつきが出るケースです。CloudWatchで実行開始時刻のばらつきが増加していることを確認できたら、ワーカー追加よりも環境クラスのアップグレード、もしくはDAGスケジュールの再構成を優先します。「同じ時刻にDAGが集中している」状態を是正するだけで、追加投資なしに改善することも珍しくありません。
パターンD/メモリリーク。ワークロードが一定もしくは減少しているのに、メタデータデータベースの FreeableMemory が低下し続けるケースです。コネクションプールの枯渇、DAGのトップレベルで Variable.get() を呼び出すなどパース毎に重い処理が走る実装が代表的な原因です。これは典型的に「ワーカーを増やしてはいけない」シナリオで、メタデータDBへの負荷を直接見直さない限り、増設は悪化要因にしかなりません。
監視と設定の実践ポイント
ワーカー増設の判断は、感覚ではなくCloudWatchメトリクスに基づいて行うべきです。Amazon MWAAでは、以下のメトリクスを AWS/MWAA 名前空間で参照できます。
CPUUtilizationおよびMemoryUtilization(Scheduler、BaseWorker、AdditionalWorkerで個別に確認可能)ApproximateAgeOfOldestTask(キュー先頭タスクの経過秒数。着実に増えるならメッセージ消費が追いついていないサイン)QueuedTasks(キューに溜まっているタスク数)RunningTasks(実行中タスク数。環境の実効並列度を把握できる)- メタデータデータベース側の
FreeableMemory(パターンDの兆候検知に有効)
運用時のおすすめ設定は、期間を1分、統計を最大値(Maximum)にしたうえで、十分な時間枠でグラフを観察することです。平均値だけを見ているとスパイクを見落とし、ピーク時に詰まる原因を取りこぼします。とくに ApproximateAgeOfOldestTask が右肩上がりに伸びているなら、まずワーカー容量とAirflow設定の両方を疑う癖をつけておくと、判断が速くなります。
環境構築・運用側で押さえておきたい設定面のチェックポイントは次のとおりです。第一に、環境クラスを変更した際は必ず celery.worker_autoscale を新しいクラスのデフォルトに合わせて手動で更新すること。第二に、DAGコードのトップレベルで重い処理(Variableの取得、外部API呼び出しなど)を行わないこと。第三に、プールのスロット数とDAGの max_active_tasks、環境の core.parallelism を一覧化し、どこが最も低い天井になっているのかを定期的に棚卸しすることです。これだけでも「増やしたのに効かない」という事故をかなり減らせます。
まとめ ― 増設は最後の選択肢として持っておく
Amazon MWAAのワーカープール最適化は、ワーカー数というハードウェア的な打ち手と、Airflow設定およびDAG設計というソフトウェア的な打ち手を、目的に応じて組み合わせる作業です。CloudWatchで現象を観測し、4つのパターンに当てはめて根本原因を特定し、設定の階層を確認したうえで、必要であれば celery.worker_autoscale や最小ワーカー数を調整する、という順序を守ることで、過剰なスケーリングを避けながら安定運用を実現できます。
「ワーカーを増やすかどうか」の前に、「なぜ詰まっているのか」を問い直すこと。Amazon MWAA運用において、コストとスループットを両立させるための最大のレバーは、その小さな問いかけにあります。日々のオペレーションのなかで、ぜひ本記事のフレームワークを判断の起点として活用してください。
























