



生成AIアプリケーションを実運用していると、必ず一度はぶつかる悩みがあります。「新しいモデルが出るたびに、プロンプトを書き直してA/Bテストを回す工数が膨大」「同じプロンプトを使い回しているのに、モデルを切り替えると精度が落ちる」というものです。AWSは2026年5月14日、こうした課題に正面から答える新機能「Advanced Prompt Optimization」をAmazon Bedrockに追加しました。本記事では、AWS公式ブログ「Amazon Bedrock introduces new advanced prompt optimization and migration tool」および公式ドキュメントを踏まえ、Advanced Prompt Optimizationの仕組み、評価方法の選択肢、ジョブ作成の実装、そしてコスト・実行時間の現実的な見積もりまでを、生成AIアプリケーションを開発・運用するエンジニア向けに整理します。
Advanced Prompt Optimizationとは何か
Advanced Prompt Optimizationは、Amazon Bedrock上でプロンプトテンプレートを自動的に書き換え、ターゲット基盤モデルでの精度・コスト・レイテンシーを定量評価したうえで、最適化されたプロンプトを返すマネージドな仕組みです。最大の特徴は、最大5つの基盤モデルを同時にターゲット指定できる点にあります。「現在運用中のモデル」をベースラインに置き、移行候補4モデルと並べて比較する使い方が、単一ジョブで完結します。
従来であれば、新しいモデルが登場するたびにエンジニアが手作業でプロンプトを書き換え、評価データセットで採点し、結果を見ながら微調整する反復作業を繰り返していました。Advanced Prompt Optimizationはこの反復ループを内部で自動化し、評価結果に基づいた書き換えをサービス側で繰り返します。エンジニアは元のプロンプトテンプレートと評価用サンプルデータ、評価方法を渡すだけで、最適化されたプロンプトを受け取れる点が新しさです。
もうひとつ重要な特徴が、マルチモーダル入力への対応です。PNG、JPG、PDFを評価サンプルに含められるため、画像分析や文書理解のプロンプトも、テキストタスクと同じワークフローで改善対象にできます。RAGや帳票読み取りのように入力が純粋なテキストではないユースケースで効果を発揮する設計です。
最適化ループとマルチモーダル対応の仕組み
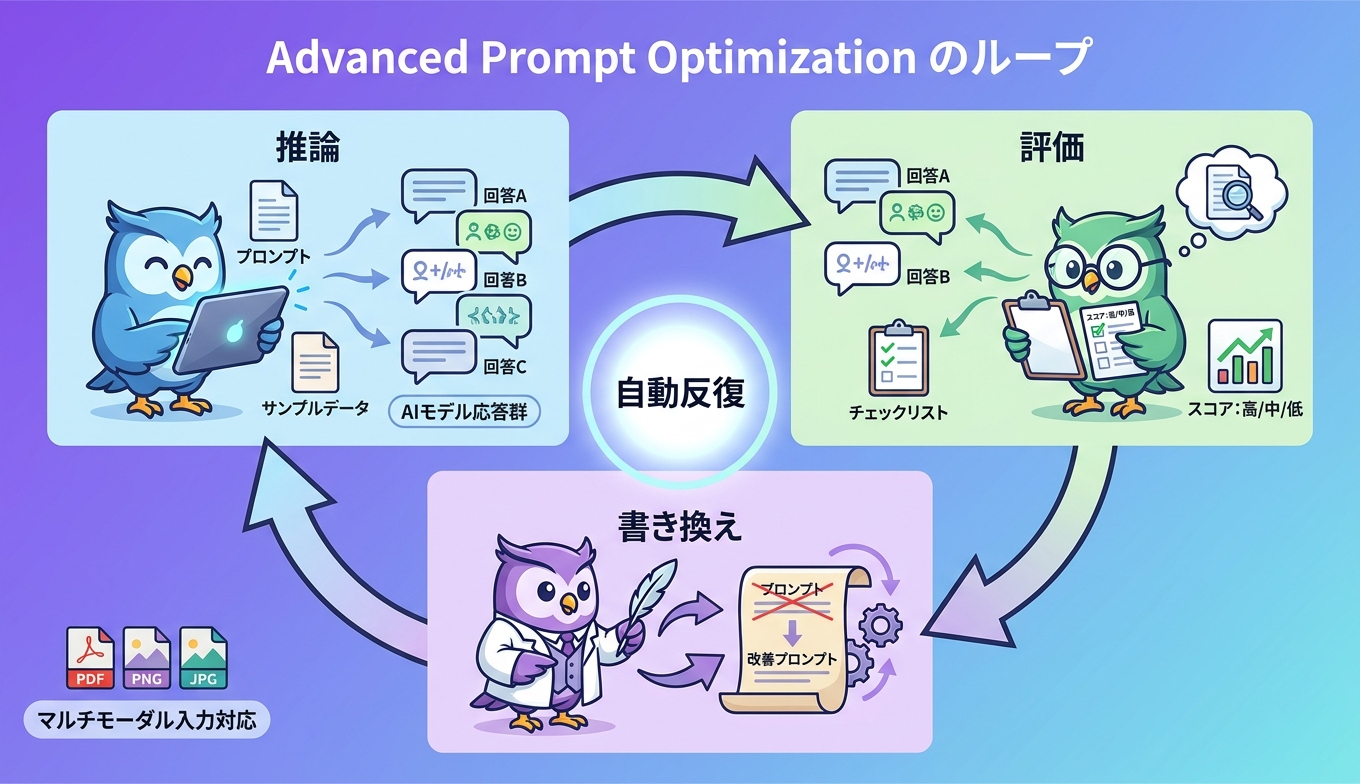
公式ドキュメントによれば、Advanced Prompt Optimizationの内部処理は「推論(inference)」「評価(evaluate)」「書き換え(rewrite)」の3ステップを反復するループとして設計されています。プロンプトテンプレート中の {{placeholder}} 変数に評価用サンプルの値が差し込まれ、ターゲットモデルへ送って応答を生成、応答を指定の評価方法で採点し、その結果を踏まえてサービスがプロンプトを書き換え、再び推論を回す、というサイクルが内部の最適化パラメータに従って完了するまで繰り返されます。
マルチモーダル入力(画像、PDF)はプロンプトと一緒にペイロードに含めてモデルに送られます。ただし画像やPDFは、テンプレートの {{placeholder}} 変数として参照する形ではなく、サンプル側の属性として渡される設計です。テンプレートには「画像を見て答えなさい」といった指示文だけを置き、実体はサンプル側に持たせる分離が前提です。
ジョブが完了すると、最適化前後のプロンプトテンプレート、評価サンプルごとのスコア、モデルごとのTTFT(time to first token)レイテンシー、コスト見積もりが結果として返ります。「どのプロンプトに書き換わったか」だけでなく「どのモデルでどれだけ速く・安く・正確に動くか」まで一枚のビューに揃うため、移行判断の根拠資料としても活用できます。
3つの評価方法と最適化のステアリング設計
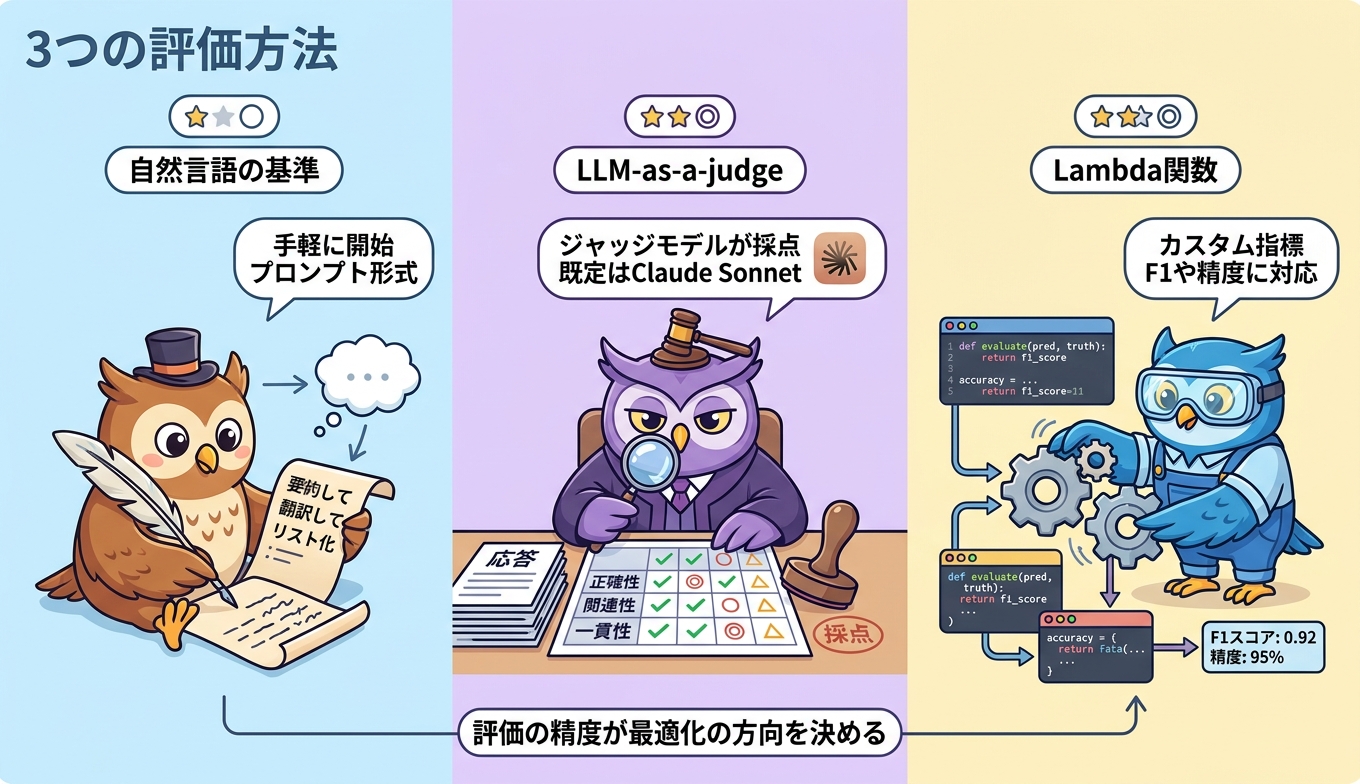
最適化ループの方向を決めるのが評価方法です。Advanced Prompt Optimizationでは、3種類の評価方法とシステムデフォルトを用途に応じて選べます。それぞれ得意領域が異なるため、最初のジョブ設計で「何を評価軸にするか」を明確にしておくことが、出てくる最適化プロンプトの品質を大きく左右します。
自然言語による評価基準(steering criteria)。もっとも手軽な選択肢で、評価観点を自然言語で記述してジョブに渡します。「事実に基づき要約は3文以内」「コードブロックは実行可能」といった品質基準をプロンプトに近い形で書けばよく、専用のジャッジ用プロンプトや関数の準備が不要です。最初の試作や定量指標が確立していない領域の探索に向きます。
LLM-as-a-judge(ジャッジモデル評価)。応答評価を別の大規模言語モデルに任せる方式です。既定のジャッジモデルはAnthropic Claude Sonnet 4.6で、カスタムLLMJプロンプトで他モデルも指定可能です。要約の流暢さや自由記述タスクなど、ルールベースで自動採点しづらいケースで威力を発揮します。評価そのものに推論コストが発生する点には注意が必要です。
Lambda関数によるカスタム評価。AWSアカウント内のAWS Lambda関数で compute_score を実装し、任意ロジックで採点する方式です。分類タスクの精度、F1スコア、編集距離、JSONバリデーションなど、決定的なメトリクスを評価軸に据えたいときに最も柔軟で、出力構造そのものを評価対象としたい場合にも適しています。
3つの評価方法は、プロンプトテンプレートごとに個別に選択できます。たとえば要約タスクのテンプレートには自然言語基準を、構造化抽出タスクにはLambdaを、と使い分けることで、ひとつのジョブで多様なタスクを同時に最適化できます。重要なのは、評価が曖昧だと最適化の方向そのものが揺らぐということです。AWS公式ドキュメントも「評価がプロンプト最適化を導くため、評価方法と基準はできる限り厳密に定義すべき」と明記しています。
ジョブ作成の流れ(コンソール・Python SDK・CLI)
Advanced Prompt Optimizationのジョブは、マネジメントコンソール、Python SDK(boto3)、AWS CLIのいずれからも作成できます。コンソールではジョブ名を付け、最大5つのターゲットモデルを選び、評価サンプルを格納したJSONLファイルをアップロードし、各プロンプトテンプレートの評価方法を指定したうえで、結果出力先のS3パスを設定すれば作成完了です。任意でジョブ説明文やカスタムKMSキー暗号化も指定できます。なお、結果ファイルを出力先のS3パスから移動するとコンソールの結果ページがレンダリングできなくなるため注意が必要です。
Python SDKでは create_advanced_prompt_optimization_job を呼び出します。最小構成は次のとおりです。
import boto3
client = boto3.client('bedrock', region_name='us-west-2')
response = client.create_advanced_prompt_optimization_job(
jobName='my-optimization-job',
modelConfigurations=[
{'modelId': 'us.anthropic.claude-sonnet-4-5-20250929-v1:0'}
],
inputConfig={'s3Uri': 's3://my-bucket/input/dataset.jsonl'},
outputConfig={'s3Uri': 's3://my-bucket/output/'}
)
job_arn = response['jobArn']
AWS CLIでも aws bedrock create-advanced-prompt-optimization-job サブコマンドで同等の操作が行えます。ジョブのステータス確認は get-advanced-prompt-optimization-job、一覧取得は list-advanced-prompt-optimization-jobs、停止は stop-advanced-prompt-optimization-job、削除は batch-delete-advanced-prompt-optimization-jobs が用意されており、CI/CDパイプラインや夜間バッチとも相性が良い構成です。
入力データセットはJSONL形式で、プロンプトテンプレートとユーザー入力サンプルをひとつのファイルにまとめます。プレースホルダー変数は {{variable_name}} の二重波括弧で記述し、サンプル側で対応する値を提供します。Lambda評価を使う場合は、評価用Lambda関数を同じAWSアカウント内にデプロイし、IAMロールから呼び出せる状態にしておく必要があります。
コストと実行時間の現実的な見積もり
Advanced Prompt Optimization自体に専用のサービス料金は設定されておらず、課金対象は「最適化中に消費されたBedrock推論トークン」と「Lambda関数の呼び出しコスト」の2つだけです。推論料金はオンデマンド推論の公開料金がそのまま適用され、LLM-as-a-judgeで採点に使われたモデルの推論コストも同じ料金体系で計上されます。料金の見積もり方法は、Bedrockの公開料金ページ「Prompt Optimization」配下の「Advanced Prompt Optimization」セクションに計算手順とともに掲載されています。
実行時間の目安も公式に示されています。プロンプト1つに少数の評価サンプルだけを与えるシンプルなジョブで15分から20分、複数プロンプトと多くの評価サンプルを組み合わせた大規模なジョブでは1時間を超え、場合によっては数時間に及ぶこともあります。理由は明快で、評価サンプル1件ごとに「推論」「評価」「書き換え」のループが複数回繰り返されるためです。サンプル数を10件から100件に増やせば、内部の推論呼び出し数も比例して膨らみます。本番運用で組み込む際には、深夜帯のバッチで回す、あるいはCI/CDではなくモデル更新時の単発タスクとして扱う、といった割り切りが現実的です。
コスト最適化の観点では、パイロット段階で評価サンプルを最小限(5件から10件程度)に絞ってジョブを試し、費用感を掴んでから拡張する進め方が無難です。LLM-as-a-judgeは強力ですが、ジャッジ側の推論コストが積み上がる点に注意し、ルールで決まる評価項目はLambda側で処理するハイブリッド構成にすると、コストパフォーマンスを引き上げやすくなります。
活用シーンと導入の進め方
Advanced Prompt Optimizationが真価を発揮するシーンは大きく3つです。第一に新モデルへの移行検証で、ベースラインと候補モデル群を同時に最適化対象にすれば、判断に必要な指標が単一ジョブで揃います。第二に既存プロンプトの段階的改善で、後付けの注釈や曖昧な指示が蓄積したプロンプトを定量根拠付きで整理できます。第三にマルチモーダルタスクの改善で、帳票OCRや図表解釈のように手チューニングが難しい領域で本機能と相性が良いです。
導入の進め方は、代表的なタスクを1つ選び、評価サンプル5〜10件・自然言語基準から開始するのがおすすめです。短時間ジョブで傾向を掴み、次の段階でLLM-as-a-judgeやLambda評価へ広げれば、評価精度を高めながらコストもコントロールできます。対応リージョンには東京も含まれており、国内ユースケースでも本番投入しやすい新機能です。プロンプトを職人技で放置せず評価データと一緒に資産化する起点として、ぜひ試してみてください。
























