



AI for Scienceとは何か——科学の共同研究者としてのAI
「AIで研究が効率化する」という段階は、もう過去のものになりつつあります。いま起きているのは、AIが科学的発見そのものを担う「共同研究者」へと進化する転換です。この新しいパラダイムが「AI for Science」です。
象徴的な出来事として、2024年のノーベル化学賞があります。DeepMindのAlphaFold開発チームを中心とした研究者たちが、AIによるタンパク質構造予測の革新的な成果を評価されました。AlphaFoldはタンパク質のアミノ酸配列から立体構造を高精度で予測するモデルであり、従来は数年を要していた構造決定をわずか数時間に短縮しました。この受賞は、AIが「研究の補助ツール」から「科学的発見の主体」へとシフトしたことを世界に示す出来事でした。
AI for Scienceが特に大きなインパクトをもたらしている分野は、創薬・ゲノミクス・材料科学の三領域です。加えて、気候科学や素粒子物理学、農業・食品科学など、データが集積されたあらゆる科学分野でAIの「科学的推論」能力が活躍しています。
これらの分野に共通するのは、探索すべき空間の広大さです。創薬では候補化合物の数は化学的に合成可能なだけで10の60乗を超えるとも言われ、ゲノムでは数十億塩基対のシーケンスから疾患に関わる変異を特定する必要があります。材料科学では、所望の特性を持つ材料を「逆設計」するには、試行錯誤の限界を超えたシステム的探索が必要です。AIはこうした広大な探索空間を、人間の直感では到達できないスピードと精度でナビゲートします。
文科省SPReAD事業の概要と申請ポイント
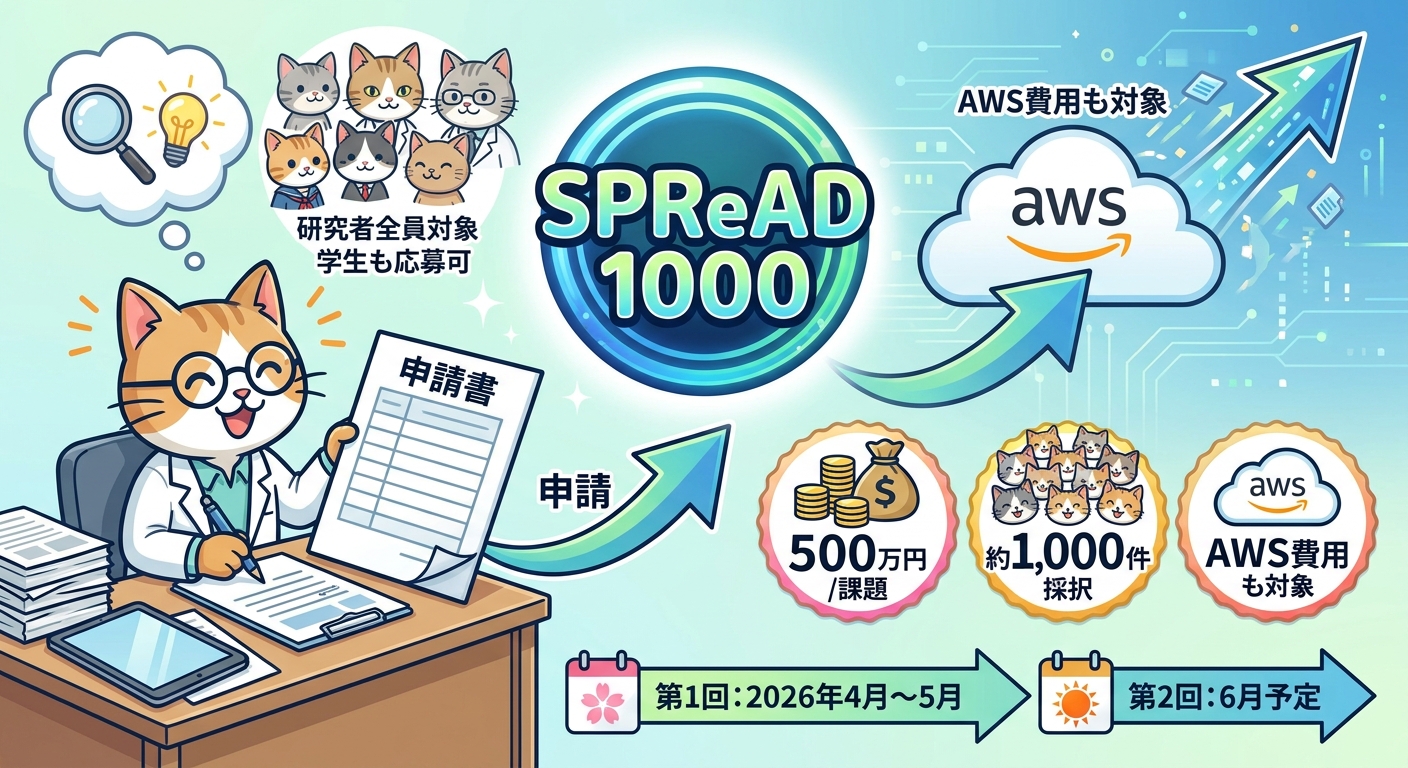
こうした潮流を受け、文部科学省は「AI for Science萌芽的挑戦研究創出事業(SPReAD)」を令和7年度補正予算で立ち上げました。SPReADはSupporting Pioneering Research through AI for 1,000 Discovery challengesの略称で、AIを活用した萌芽的・探索的な科学研究を国が広く後押しする施策です。
特筆すべきは採択規模と支援内容です。1課題あたり500万円以下(直接経費)に加えて間接経費30%が配分され、2回の公募を通じて計約1,000件の採択を目標としています。総額にして約50億円規模の投資となります。
スケジュールは以下の通りです。第1回公募は2026年4月17日に開始し、2026年5月18日正午が締切です。研究期間は交付決定日から2027年1月6日まで。第2回公募は2026年6月上旬を予定しています。第1回に間に合わなかった研究者も第2回を狙う余地があります。
応募資格は、日本国内の大学・高等専門学校・大学共同利用機関法人・独立行政法人等に所属し、研究活動に実際に従事する者です。有給・無給、常勤・非常勤を問わず、学生も応募できます。AI活用の経験は必須ではなく、AI初心者の研究者も歓迎される設計になっています。
エンジニア・研究者にとって重要なポイントは、計算資源に係る経費・データ取得利用料・API利用料が対象経費に含まれる点です。AWSをはじめとするクラウドサービスの利用料は「計算資源に係る経費」として申請できると解釈できます(詳細は公募要領の確認を推奨します)。一方、人件費は対象外です。他の競争的研究費との重複制限はARiSE(AI for Science革新的研究推進事業)との間のみに限られており、他の補助金を受けながらSPReADに並行応募することが可能です。
創薬・ゲノミクス・材料科学でのAI活用ユースケース
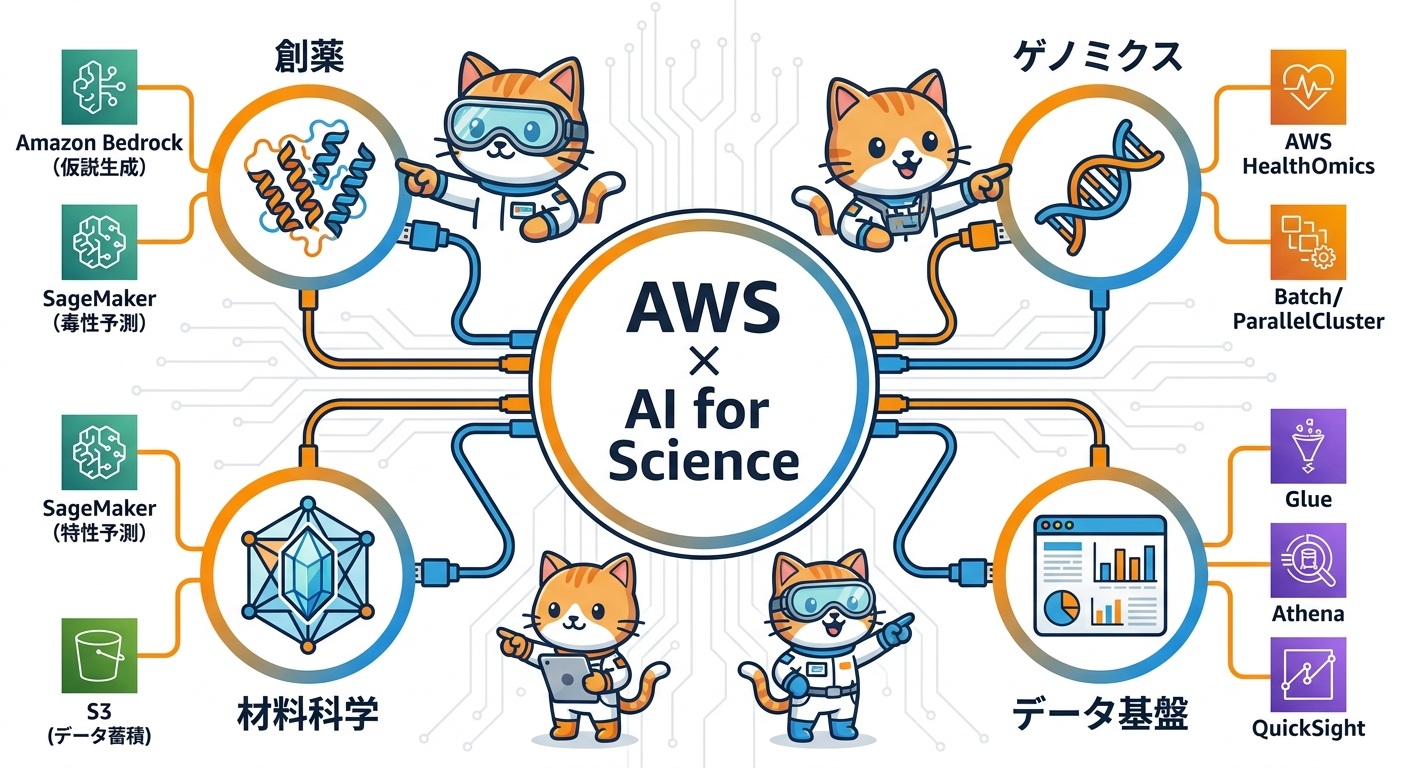
SPReADが支援対象とする全分野の中で、特にAIの力が際立っているのが創薬・ゲノミクス・材料科学の3領域です。それぞれの最前線を見ていきます。
創薬
AlphaFoldの登場以来、タンパク質の立体構造予測は研究者の手の届くツールになりました。構造情報をもとに、どの化合物がそのタンパク質に結合して機能を調節するかを「構造ベース創薬設計」と呼びます。AIは候補化合物を仮想空間で大規模スクリーニングし、実験に値するものだけを絞り込みます。これにより、合成・試験のコストと時間を大幅に削減できます。
さらに先を行くのが生成生物学(ジェネレーティブ・バイオロジー)です。AWSはEvolutionaryScaleと連携し、まったく新しいタンパク質配列を生成AIで設計するアプローチを支援しています。自然界には存在しないタンパク質を「設計」することで、既存の薬では到達できない治療ターゲットへの道が開けます。毒性予測のMLモデル構築にはAmazon SageMaker AIが活用され、前臨床段階での候補化合物の絞り込みを加速します。
ゲノミクス
ゲノム解析の世界では、ディープラーニングが遺伝子配列の変異同定とパターン認識を大幅に加速しています。1人分の全ゲノムシーケンスデータは数十ギガバイトに達し、集団規模の解析ではペタバイト級のデータを扱います。こうした大規模ゲノムデータの管理・解析に特化したサービスがAWS HealthOmicsです。
AWS HealthOmicsはゲノム・トランスクリプトーム・プロテオームなどのマルチオミクスデータを統合管理し、分析ワークフローをスケーラブルに実行する基盤を提供します。配列解析の計算集約的な処理にはAWS BatchやAWS ParallelClusterが使われ、HPCクラスタのオーケストレーションをクラウド上で実現します。
材料科学
材料科学では、「欲しい特性を持つ材料を探す」という問題が「逆設計」へと変わりつつあります。従来は多数の材料を合成して特性を測定する「試行錯誤」でしたが、機械学習モデルが材料の構造から特性を予測できるようになり、「この特性を持つ材料はどんな構造か」を逆算するアプローチが現実になっています。
太陽電池の効率改善・超電導体の探索・電池材料の最適化など、従来は何年もかかっていた探索を、AIが膨大な候補空間を高速でサーチすることで短縮します。特に量子化学計算とMLの組み合わせは、第一原理計算のコストを大幅に下げながら精度を維持する手法として研究が加速しています。
研究をAWSで実装する——Bedrock・SageMaker・HealthOmics等の対応
AI for Scienceの研究をAWS上で実装する際、どのサービスをどの用途に使うかを整理します。
仮説生成・文献解析・自然言語処理を伴う研究ではAmazon Bedrockが中核になります。BedrockはClaude・Llama・Amazon Nova等の主要基盤モデルにサーバーレスでアクセスできるマネージドサービスです。東京リージョン(ap-northeast-1)で利用できるため、研究データを国内に保持したまま大規模言語モデルを活用できます。文献サーベイの自動化、研究計画書の草案作成、実験結果の解釈補助など、研究プロセスのあらゆる局面で役立ちます。
特定ドメインのデータで事前学習済みモデルをファインチューニングしたい場合はAmazon SageMaker AIが主役です。ゲノム配列データや化学構造データを使い、ドメイン特化モデルを継続的に訓練・評価・デプロイできます。SageMakerのML Spacesとコラボレーション機能は、研究室内での共同実験管理にも適しています。
大規模なデータ基盤にはAmazon S3を中核に据えます。ゲノム配列データから気候科学の衛星画像、化学分光データまで、多様な研究データを統一的に管理できます。AWS Glue Data Catalogでメタデータを管理し、Amazon Athenaでサーバーレスにクエリを発行、Amazon QuickSightで可視化するパイプラインが標準的な構成です。
計算化学シミュレーションや大規模バイオインフォマティクス処理など、HPCが必要な場面ではAWS BatchとAWS ParallelClusterが機能します。ジョブキューの管理・計算ノードの自動スケーリング・コスト最適化を組み合わせることで、オンプレミスHPCクラスタに比べて初期投資なく大規模計算を開始できます。
顕微鏡・スペクトロメーターなどの研究機器から発生するデータを安全にクラウドへ転送するにはAWS DataSyncとAWS Storage Gatewayが役立ちます。長期保管が必要な生データのアーカイブにはAmazon S3 Glacierの活用が経済的です。
研究者がAWSを活用するための第一歩
SPReADへの応募を検討している研究者にとって、AWSをどこから始めるかは現実的な問いです。AI活用経験は不問ですが、計算資源費用を適切に見積もって申請書に盛り込む必要があります。
最初のステップとして、Amazon BedrockのコンソールでClaude等のモデルを試すことを勧めます。AWSアカウントを作成し、東京リージョンでBedrockを有効化するだけで、APIを通じて大規模言語モデルを利用できるようになります。トークン単価制で従量課金のため、小規模な実験から始めてコストを確認しながらスケールアップできます。
ゲノムデータを扱う場合は、AWS HealthOmicsのプライベートシーケンスストアにデータを格納し、標準的なバイオインフォマティクスワークフロー(WDL・Nextflow等)をReadyRunsとして実行できます。ゲノム解析環境のセットアップに時間をかけることなく、解析そのものに集中できる設計です。
SPReADの申請書を書く際には、使用するAWSサービスと想定規模を具体的に記載することが重要です。Bedrock APIの呼び出し回数・SageMakerのインスタンス時間・S3のストレージ量・Batchの計算ジョブ数などを見積もり、月次コストをAWS料金計算ツールで算出して直接経費に計上します。500万円の上限内であれば、相当規模のクラウド計算を1年間実行できます。
AWS Educateや研究機関向けの無料クレジットプログラムを組み合わせることで、申請前の実験フェーズのコストを抑えることも可能です。本番応募前に小規模PoC(概念実証)を済ませておくと、申請書の説得力が増します。
まとめ——AI for Scienceの波に乗るために
AI for Scienceは、科学研究の進め方そのものを塗り替えるパラダイムシフトです。2024年ノーベル化学賞が示したように、AIによる科学的発見はすでに現実のものです。創薬・ゲノミクス・材料科学を筆頭に、AIが探索できる問題の質と量は人類の研究能力を根底から拡張しています。
文科省SPReADは、この潮流にエンジニアや研究者が乗り込むための具体的な入口です。1課題500万円・約1,000件採択・クラウド費用対象というスケールは、「やってみたいがリソースがない」という研究者の障壁を大きく下げます。第1回公募の締切は2026年5月18日正午、第2回は6月上旬を予定しています。
AWSはAmazon Bedrock・SageMaker AI・AWS HealthOmics・S3・Batch・ParallelClusterといったサービス群で、AI for Scienceの研究インフラを包括的に支えます。クラウドの弾力性により、大規模計算が必要な実験フェーズだけリソースを増やし、アイドル時はコストを最小化できます。これはオンプレミスHPCにはない研究者フレンドリーな特性です。
AI初心者でも応募できるSPReADと、さまざまな研究規模に対応するAWSの組み合わせは、日本の科学研究が世界の最前線に立つための有力な手段になり得ます。自分の研究テーマにAIを掛け合わせる可能性を、ぜひ今すぐ考えてみてください。









.webp?q=65&fm=webp&w=400&h=260&fit=crop)














