



FAISSエンジンによるベクトル検索と発生しやすい問題
Amazon OpenSearch Serviceでは、RAG(Retrieval-Augmented Generation)や類似文書検索などのユースケースに対応するために、ベクトル検索機能が広く活用されています。その中でもFAISSエンジン(Facebook AI Similarity Search)は、高速な近似最近傍探索(ANN)を実現するエンジンとして多くのシステムに採用されています。
しかし、本番環境でのデータ投入を進めると「書き込みが途中で失敗する」「インデックス作成が不安定になる」「突然レスポンスが返らなくなる」といったトラブルに遭遇することがあります。こうした問題の多くは、メモリとディスクに関するリソース制限が原因です。
本記事では、FAISSエンジンを使ったベクトル検索でよく発生するデータ投入失敗の原因を詳しく解説し、それぞれの状況に応じた実践的な対処法を紹介します。
データ投入失敗の原因1 - KNNグラフメモリとサーキットブレーカー
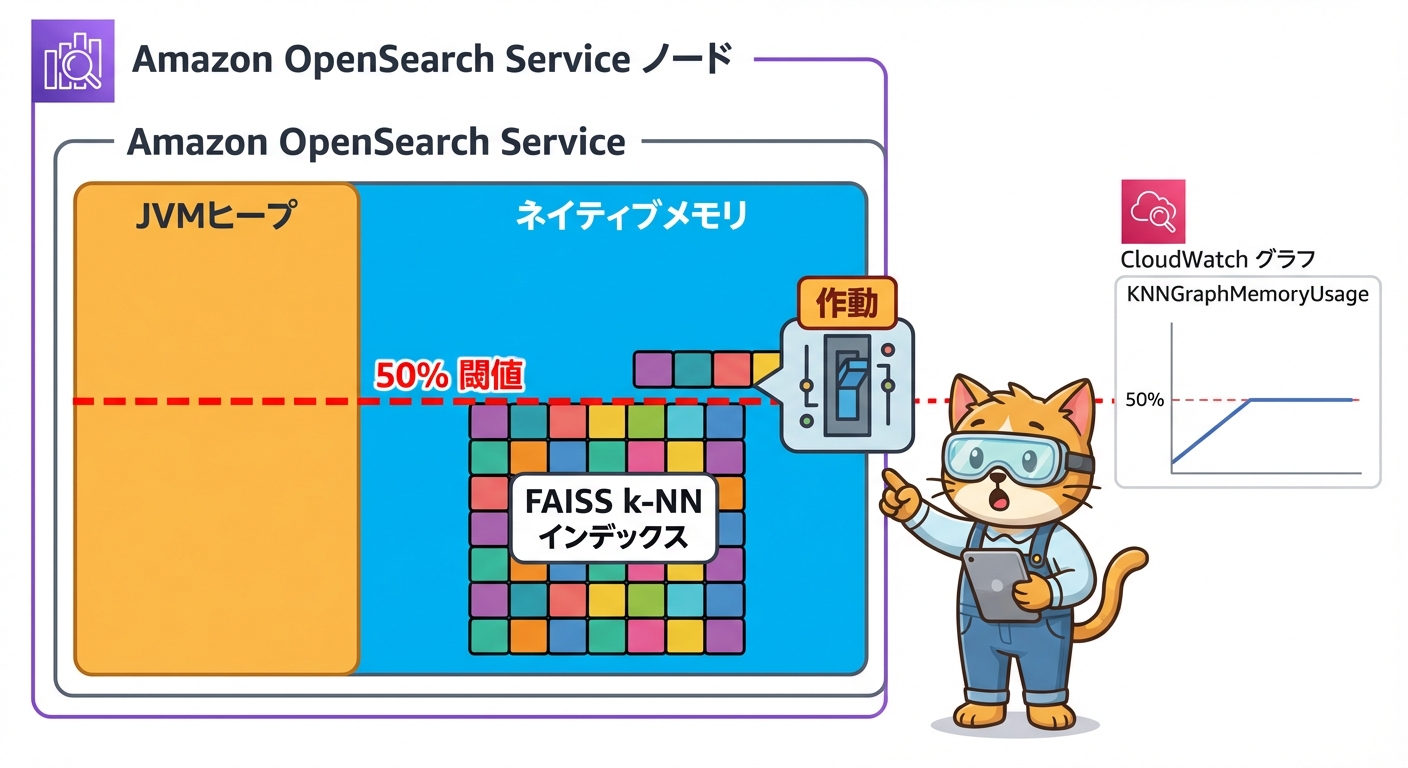
FAISSエンジンを使用したベクトル検索では、インデックスのKNNグラフがJVMヒープではなくネイティブメモリ(オフヒープメモリ)に格納されます。このネイティブメモリの使用状況は KNNGraphMemoryUsage メトリクスで確認できます。
デフォルト設定では、JVMヒープサイズはノードの物理メモリの50%か32GBの大きい方が割り当てられます。つまり、残りのメモリがFAISSのネイティブキャッシュや他のプロセスに使われる形になります。
問題になるのは、このネイティブメモリ使用量が増加した際にサーキットブレーカーが発動する点です。サーキットブレーカーの閾値は knn.circuit_breaker.limit パラメータで制御されており、デフォルトは50%です。この閾値を超えると、KNN検索やインデックス更新がブロックされ、書き込みエラーが発生します。
現在のKNN統計情報は以下のAPIで確認できます。
GET /_plugins/_knn/statsこのレスポンス内の circuit_breaker_triggered が true になっていれば、サーキットブレーカーが発動した状態です。また knn_query_requests や graph_memory_usage の値から、現在のメモリ使用状況を把握できます。
サーキットブレーカーが頻発する場合は、knn.circuit_breaker.limit を調整するよりも、根本的なメモリ使用量を削減する量子化やMemory Optimized Searchの導入を検討することが推奨されます。
データ投入失敗の原因2 - ディスク容量不足による書き込みブロック
もう一つのよくある原因が、ディスク容量不足です。Amazon OpenSearch Serviceは、内部的なマージ操作やスナップショットなどのために、ディスク容量の一定割合を予約しています。
具体的には、空き容量が「利用可能なストレージの20%」または「20GiB」の小さい方を下回ると、インデックスへの書き込みが自動的にブロックされます。この状態では新規ドキュメントの追加やインデックスの更新ができなくなり、書き込みエラーが発生します。
CloudWatchの FreeStorageSpace メトリクスを監視し、閾値アラートを設定しておくことで事前に対処が可能です。特にベクトルインデックスはテキストインデックスと比べてデータサイズが大きくなりやすいため、ディスク使用量の増加速度も速い傾向があります。

メモリ問題への対処法 - 量子化とMemory Optimized Search
ネイティブメモリの使用量を削減するための主な手法が量子化です。量子化とは、ベクトルデータを圧縮してメモリ消費を削減する技術で、OpenSearch Serviceでは以下の方式をサポートしています。
バイナリ量子化は各次元を1ビットで表現する最も積極的な圧縮方式で、最大32倍の圧縮率を実現します。検索精度は低下しますが、メモリ使用量の削減効果は最大です。大規模コーパスへの初期適用や、精度よりもコストを優先する場面に向いています。
バイト量子化(int8)は各次元を8ビット整数で表現し、float32と比較して約1/4のメモリ量に削減できます。精度と圧縮率のバランスが良く、多くのユースケースで実用的な選択肢です。
FP16量子化は16ビット浮動小数点を使用し、約1/2の圧縮率です。精度をほとんど落とさずにメモリを削減したい場合に適しています。
直積量子化(PQ)はベクトルをサブベクトルに分割してそれぞれを独立に量子化する手法で、最大64倍の圧縮率を実現できます。ただし事前のトレーニングデータが必要で、インデックス作成の手間が増えます。
また、OpenSearch 3.1以降ではMemory Optimized Searchが利用可能です。これはLuceneとFAISSのハイブリッドアプローチで、reindexを行わずに3〜4倍のメモリ削減が期待できます。既存のインデックスに対してもダウンタイムなしで適用できる点が大きなメリットです。
ディスク問題への対処法 - Disk modeとEBSボリューム拡張
ディスク容量不足に対しては、いくつかのアプローチがあります。
OpenSearch 2.17以降で利用可能なDisk modeは、量子化されたベクトルをメモリに保持しつつ、完全精度のベクトルをディスクに格納する方式です。compression_level パラメータで圧縮率を制御でき、1x / 2x / 8x / 16x / 32x の中から選択できます。メモリとディスクのトレードオフを柔軟に調整できるため、大規模なベクトルデータを扱うシステムに特に有効です。
EBSボリュームの追加も有効な手段です。Amazon OpenSearch Serviceでは最大1536GiBまでEBSボリュームを拡張できます。CLIコマンドを使ったオンライン変更に対応しており、ダウンタイムなしでストレージを増設できます。ただし、ボリュームの縮小は行えないため、必要な容量を見積もってから実施することをおすすめします。
ディスク容量の逼迫を防ぐためには、不要なインデックスの定期的なクリーンアップや、ISM(Index State Management)ポリシーによるインデックスのライフサイクル管理も組み合わせると効果的です。
まとめ - 安定したベクトル検索運用のために
Amazon OpenSearch ServiceのFAISSエンジンを使ったベクトル検索でのデータ投入失敗は、主に以下の2つが原因です。
- KNNグラフのネイティブメモリ超過によるサーキットブレーカーの発動
- ディスク残量不足による書き込みブロック
メモリ問題への対処としては、量子化(バイナリ・バイト・FP16・PQ)やMemory Optimized Searchの導入が効果的です。ディスク問題に対しては、Disk modeの活用やEBSボリュームの拡張が有効です。
どの手法を選ぶかは、データ規模、必要な検索精度、コスト、バージョン制約によって異なります。まずは GET /_plugins/_knn/stats と CloudWatch の FreeStorageSpace メトリクスで現状を把握し、ボトルネックに応じた対策を選択することが重要です。
ベクトル検索の安定運用には事前のキャパシティプランニングが欠かせません。本番環境に投入する前に、量子化の圧縮率と検索精度のトレードオフを評価し、適切なインスタンスタイプとストレージ設定を選定することをおすすめします。
























