



Spanner Omniとはどのような製品か
2026年4月23日、ラスベガスで開催されたGoogle Cloud Next 2026において、Googleはオンプレミス環境にインストールできる大規模分散リレーショナルデータベース「Spanner Omni」のプレビュー版を公開しました。Google Cloud Spannerは2017年の一般公開以来、金融・eコマース・ゲームなど高い一貫性とスケーラビリティを求める領域で広く採用されてきたクラウドネイティブの分散RDBです。Spanner Omniはそのコア技術を、Google Cloudの外——オンプレミスのデータセンター、セカンダリクラウド、あるいはローカルのノートPCにまでインストール可能にした製品です。
Googleの公式情報によれば、Spanner OmniはSpannerの業界トップクラスのスケール・高可用性・強整合性をオンプレミス・マルチクラウド・ラップトップ上のインフラに拡張するものとして位置付けられています。スケーラビリティの面では、単一サーバから数千台規模のクラスタへと柔軟に拡張可能であり、Googleのベンチマークによればシングルリージョンのデプロイにおいてペタバイト規模のデータに対して秒間数百万件のQPS処理が実証されています。
Cloud Spannerとの違いと技術的な挑戦
Google Cloud SpannerとSpanner Omniの最大の違いは、動作基盤にあります。Google Cloud Spannerはその強力な性能を実現するために、Googleが社内で構築した2つの専有技術——ColossusとTrueTime——に依存しています。この2つの技術をオンプレミス環境向けに再設計することが、Spanner Omni開発における最大の技術的挑戦でした。
比較項目 | Google Cloud Spanner | Spanner Omni |
|---|---|---|
動作環境 | Google Cloud専用 | オンプレミス・他クラウド・ローカル |
ストレージ基盤 | Colossus(Google独自分散ストレージ) | ローカルファイルシステム抽象化レイヤー |
時刻同期 | TrueTime(原子時計・GPSハードウェア) | ソフトウェアベースの時刻同期ソリューション |
管理形態 | フルマネージド | セルフマネージド(プレビュー段階) |
スケール | グローバルマルチリージョン対応 | 単一サーバ〜数千台クラスタ |
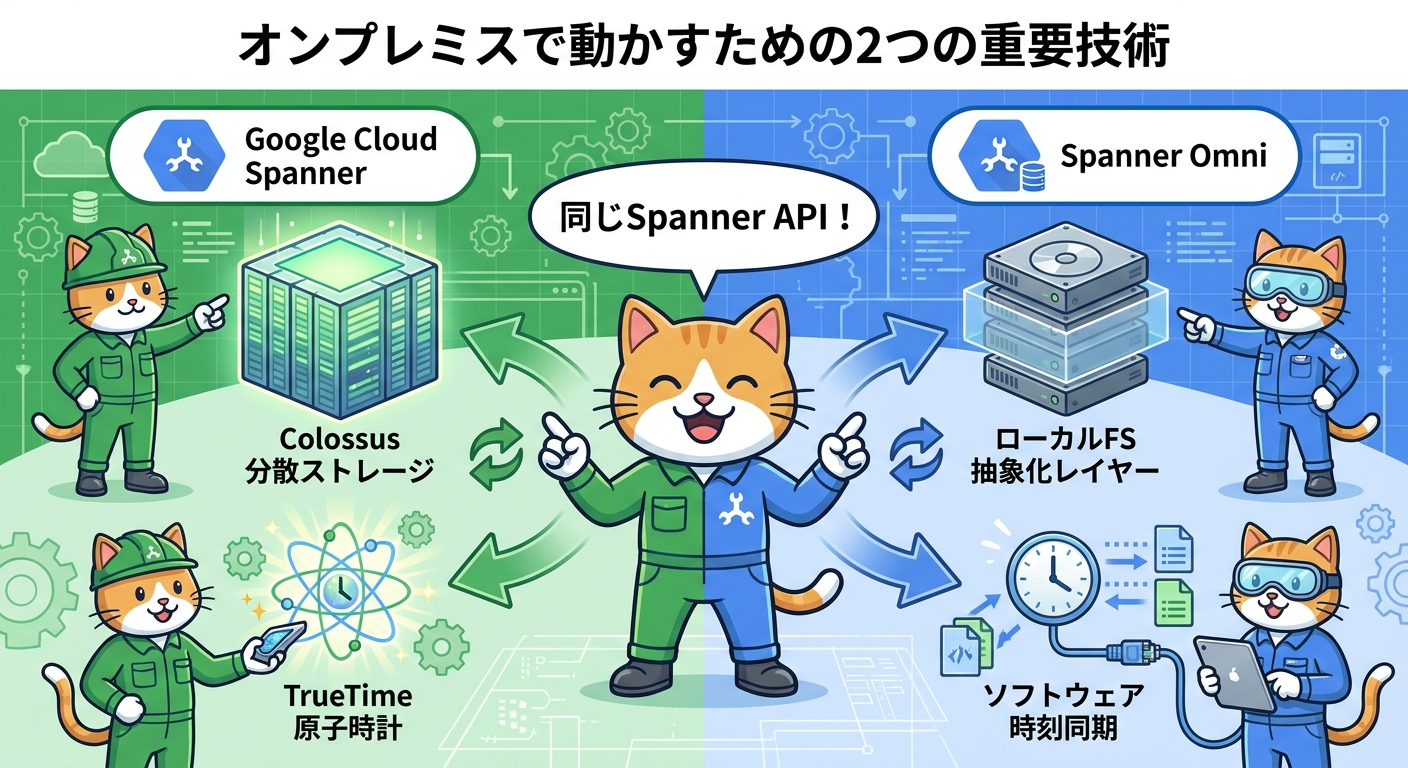
オンプレミスで動かすための2つの重要技術
Spanner Omniがオンプレミス環境で機能するために、Googleが取り組んだ2つの主要な技術的課題と、その解決アプローチを解説します。
Colossus抽象化レイヤー
Google Cloud SpannerはGoogleの社内分散ファイルシステム「Colossus」の上に構築されています。Colossusはデータの自動レプリケーション、シャーディング、負荷分散を担う非常に高度なシステムですが、当然ながらGoogle Cloudの外では利用できません。Spanner Omniでは、このColossusの役割をローカルファイルシステム上で再現する抽象化レイヤーが実装されました。このレイヤーは接続されたローカルファイルシステムにデータを書き込み、ネットワーク経由で他ノードからアクセス可能にします。また、自動的なシャード分割と再配置によりサーバ間のストレージバランスを最適化する仕組みも含まれており、汎用的なサーバ群の上でもSpannerの分散ストレージの特性を引き継ぐことが可能になっています。
TrueTimeの代替実装
Google Cloud Spannerの強整合性分散トランザクションの核心にあるのが「TrueTime」です。TrueTimeは原子時計とGPSレシーバーを使用してナノ秒レベルの精度で時刻を管理し、分散環境でのトランザクション順序保証を実現するGoogleの専用技術です。しかし、一般的なオンプレミス環境にはこのような専用ハードウェアがありません。そこでSpanner Omniでは、ソフトウェアベースの時刻同期ソリューションが開発されました。Google Cloud版のTrueTimeと同様に誤差範囲が限定された信頼性の高い時刻同期を実現しており、専用ハードウェアなしでも分散トランザクションの強整合性が維持される設計になっています。
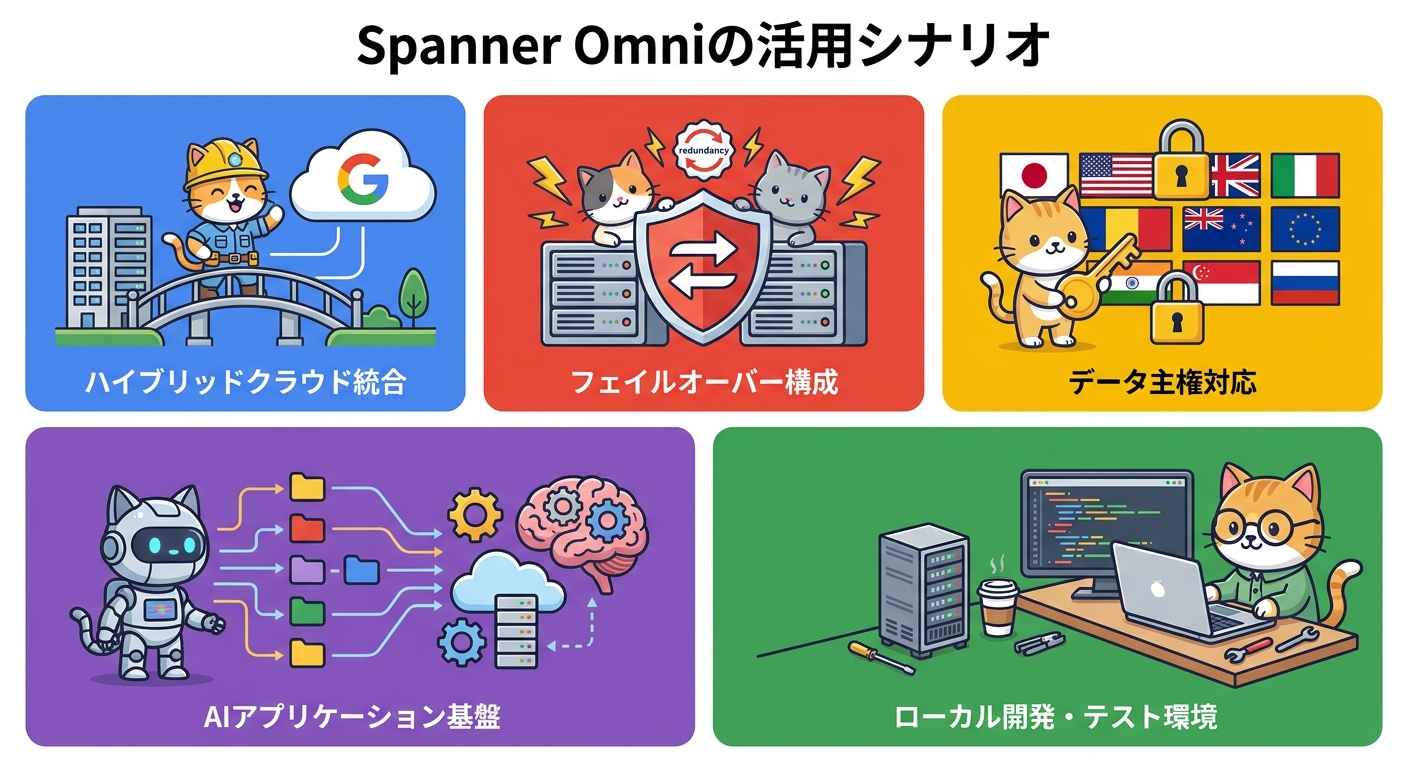
想定されるユースケースと活用シナリオ
Spanner Omniが提供する「クラウドとオンプレミスで同一のDB層を持てる」という特性は、いくつかの重要なシナリオで力を発揮します。
シナリオ | 内容 | 主な対象 |
|---|---|---|
ハイブリッドクラウド統合 | Google Cloud SpannerとオンプレミスSpanner Omniで同一DBスキーマ・APIを維持 | 段階的クラウド移行中の企業 |
フェイルオーバー構成 | Google Cloud Spannerのホット/コールドフェイルオーバーサイトとしてオンプレミスを活用 | 金融・医療・公共など高可用性必須の業種 |
データ主権対応 | 規制上クラウドに置けないデータをオンプレミスで管理しつつSpannerと同等の機能を享受 | 金融機関・行政・医療機関 |
AIアプリケーション基盤 | スケーラビリティと強整合性を必要とするAIアプリの基盤としてオンプレミスで構築 | エンタープライズAI開発チーム |
ローカル開発・テスト環境 | ノートPCにインストールしてCloudと同一環境でローカル開発・テストを実施 | 開発者・QAエンジニア |
特に注目すべきはデータ主権(データレジデンシー)対応のユースケースです。金融機関や公共機関では「データを自国または自社施設に置かなければならない」という法規制・コンプライアンス要件を持つケースが多くあります。これまでこのような制約がある場合はSpannerの利用を諦めるか、別の分散DBを採用するしかありませんでした。Spanner Omniはこの課題に対して有力な解決策となる可能性があります。
競合製品との比較とSpanner Omniの位置付け
Google Cloud Spannerが2017年に登場した後、その設計思想に影響を受けたオープンソースや商用の分散RDBが多数登場しました。CockroachDB、TiDB、YugabyteDBなどはSpannerより早くオンプレミス対応を実現しており、市場でのシェアを獲得してきました。
製品名 | タイプ | オンプレミス対応 | 主な特徴 |
|---|---|---|---|
Spanner Omni | 商用(Google Cloud) | 対応(プレビュー) | Google製、Google Cloud Spannerと完全互換 |
CockroachDB | 商用/OSS | 対応(GA) | Spannerインスパイア、PostgreSQL互換 |
TiDB | OSS/商用 | 対応(GA) | MySQL互換、HTAP対応 |
YugabyteDB | OSS/商用 | 対応(GA) | PostgreSQL互換・Cassandra互換 |
競合製品と比較してSpanner Omniの強みは「Google Cloud Spannerとの完全な互換性」にあります。すでにGoogle Cloud Spannerを本番で使っている企業にとって、オンプレミスや別のクラウド環境に同じコードベース・スキーマでSpannerを展開できることの価値は大きいです。現時点ではプレビュー段階であり、フルマネージドサービスとしてのGoogle Cloud Spannerと異なりセルフマネージドでの運用が必要になります。
クラウドネイティブ移行における戦略的な意味
Ragate株式会社はサーバーレス・クラウドネイティブ・生成AIを活用したIT/DXプロジェクトの支援を行っており、特に「段階的かつ確実なクラウドネイティブ移行」を得意領域としています。代表・益子竜与志氏の著書『AI駆動で進める「小さく確実な」クラウドネイティブ移行』(技術評論社、2026年3月)でも解説されているように、クラウド移行は段階的アプローチが現実的です。
この文脈において、Spanner Omniは非常に重要な意味を持ちます。クラウド移行の大きな障壁のひとつが「データベース層の移行」です。アプリケーション層はコンテナ化・サーバーレス化によって比較的移行しやすくなっていますが、データベースはデータ移行のリスク、ダウンタイム、互換性問題から移行が後回しにされがちです。
Spanner Omniが提供するのは、この移行を段階的に進めるためのブリッジです。まずオンプレミスのSpanner Omniで新システムを稼働させ、データの整合性を確認しながらGoogle Cloud Spannerへ段階的に移行する——あるいはハイブリッド構成を維持しながら徐々にクラウド比率を高める——こうした柔軟なアプローチが可能になります。また、開発・テスト・ステージング環境をSpanner Omniで構築し、本番のみGoogle Cloud Spannerを使うという環境分離戦略も考えられます。Spanner Omniはまだプレビュー段階ですが、クラウドネイティブへの移行を進める企業にとって、データベース層の選択肢が広がったことは確かです。今後のアップデートと正式リリースを注視していく価値のある技術として、継続的なキャッチアップをお勧めします。









.webp?q=65&fm=webp&w=400&h=260&fit=crop)














