



2026年3月31日、AI業界に静かな衝撃が走りました。カリフォルニア工科大学(Caltech)出身の数学者チームが設立したスタートアップ・PrismMLが、ステルスモードから突如姿を現し、「1ビットBonsai 8B」を公開したのです。
このモデルが業界を驚かせた理由はシンプルです。8.2Bパラメータを持つ大規模言語モデルでありながら、必要なメモリはたったの1.15GB。フルprecision(16ビット)の同等モデルと比べて14倍以上小さく、それでいて精度では互角以上の性能を発揮するのです。iPhoneで秒間44トークンを生成し、M4 Proのマシンでは秒間131トークンを達成する。これはかつて「クラウド専用」とされてきた高性能AI推論が、一般的なデバイスで動く現実が到来したことを意味します。
本記事では、1ビットBonsai 8Bの技術的な仕組みと実力、そして私たちエンジニアが今すぐ活用できるシナリオについて詳しく解説します。
1ビットBonsai 8Bとは何か
Bonsai 8Bは、PrismMLが開発した「世界初の商用実用可能なエンドツーエンド1ビットLLM」です。PrismMLはCaltech数学者のBabak Hassibiが共同創業し、Khosla Ventures、Cerberus Capital、Caltechが主導した1,625万ドルの資金調達ラウンドで立ち上がりました。
モデルの詳細仕様は次のとおりです。
- パラメータ数:8.19B(埋め込み除く約6.95B)
- デプロイサイズ:1.15GB(MLX形式)/ 1.28GB(GGUF形式)
- ベースアーキテクチャ:Qwen3-8B dense
- コンテキスト長:65,536トークン
- ライセンス:Apache 2.0(商用利用自由)
- 対応フォーマット:MLX(Apple Silicon向け)、GGUF(llama.cpp/CUDA向け)
注目すべきは「エンドツーエンド」という点です。従来の量子化アプローチでは、埋め込み層やLMヘッドなど一部に16ビット精度を残す「逃げ道」を設けることが一般的でした。Bonsai 8Bでは、埋め込み、アテンション射影、MLP射影、LMヘッドのすべてが1ビットで実装されています。これはモデル全体を通じた真の1ビットモデルです。
モデルファミリーとして、Bonsai 1.7B(0.24GB)、Bonsai 4B(0.57GB)も同時に公開されており、デバイスのスペックに合わせた選択が可能です。
なぜ1ビット量子化がゲームチェンジャーなのか

AIモデルの重みは通常、浮動小数点数(FP32やFP16)で表現されます。16ビット表現では1つの重みに2バイト使用するため、8.2Bパラメータのモデルは単純計算で約16GBのメモリを必要とします。これがiPhoneに載らない理由でした。
1ビット量子化では、各重みを「0」または「1」の1ビット値に変換します。Bonsai 8Bが採用する「1-bit g128」形式では、128個の重みのグループごとに1つのFP16スケール因子を共有することで精度の損失を最小化しています。計算式でいえば、重みwは「w = scale × bit」で表現されます(0は-scale、1は+scaleに対応)。
しかし1ビット化の本質は単なるサイズ削減ではありません。PrismMLが提唱するのが「インテリジェンス密度(Intelligence Density)」という概念です。これは「モデルがサイズあたりにどれだけの知能を持つか」を数値化したもので、平均エラー率の対数の負値をモデルサイズ(GB)で割って算出します。
この指標で比較すると、Bonsai 8Bは1.062/GBに対し、Qwen3 8Bは0.098/GB、Llama 3.1 8Bは0.074/GBとなります。Bonsai 8BはQwen3 8Bの10倍以上のインテリジェンス密度を持つ計算です。
同社CEOのBabak Hassibiは「ニューラルネットワークをその推論能力を失わずに圧縮するための数学的理論の開発に何年もかけた」と語っており、この技術がCaltech発の深い数学的研究に基づくことがわかります。
ベンチマークで見る実力と速度
Bonsai 8Bのベンチマーク結果(PrismML公表値)は次のとおりです。評価は6つのカテゴリ(IFEval、GSM8K、HumanEval+、BFCL、MuSR、MMLU-Redux)の平均スコアで測定されています。
モデル | サイズ | 平均スコア |
|---|---|---|
1-bit Bonsai 8B | 1.15 GB | 70.5 |
Llama 3.1 8B(FP16) | 16 GB | 67.1 |
Ministral3 8B(FP16) | 16 GB | 71.0 |
Qwen3 8B(FP16) | 16 GB | 参考 |
フルprecisionの8Bモデルたちと比べて遜色のない、それどころか上回る精度をわずか1.15GBで達成しています。
速度面でも驚異的な数字が並びます。
デバイス | 速度(tok/s) | 標準16bit 8Bとの比較 |
|---|---|---|
M4 Pro Mac | 131 tok/s | 8.4倍高速 |
RTX 4090 | 368 tok/s | 6.2倍高速 |
iPhone 17 Pro Max | 44 tok/s | (16bit 8Bは動作不可) |
特筆すべきはエージェンティックタスクでの性能です。50件のチケットサマリー・割り当てタスクをシミュレートした実験では、同一時間内でBonsai 8Bが50件すべてを完了したのに対し、標準の16ビット8Bモデルはわずか6件しか処理できませんでした。メモリフットプリントの小ささが、長時間・多ステップのエージェント処理においても圧倒的な優位性をもたらしています。
エネルギー効率についても16ビットモデルの4〜5倍の効率を実現しており、M4 Proで0.074 mWh/token、iPhone 17 Pro Maxで0.068 mWh/tokenという低消費電力を達成しています。
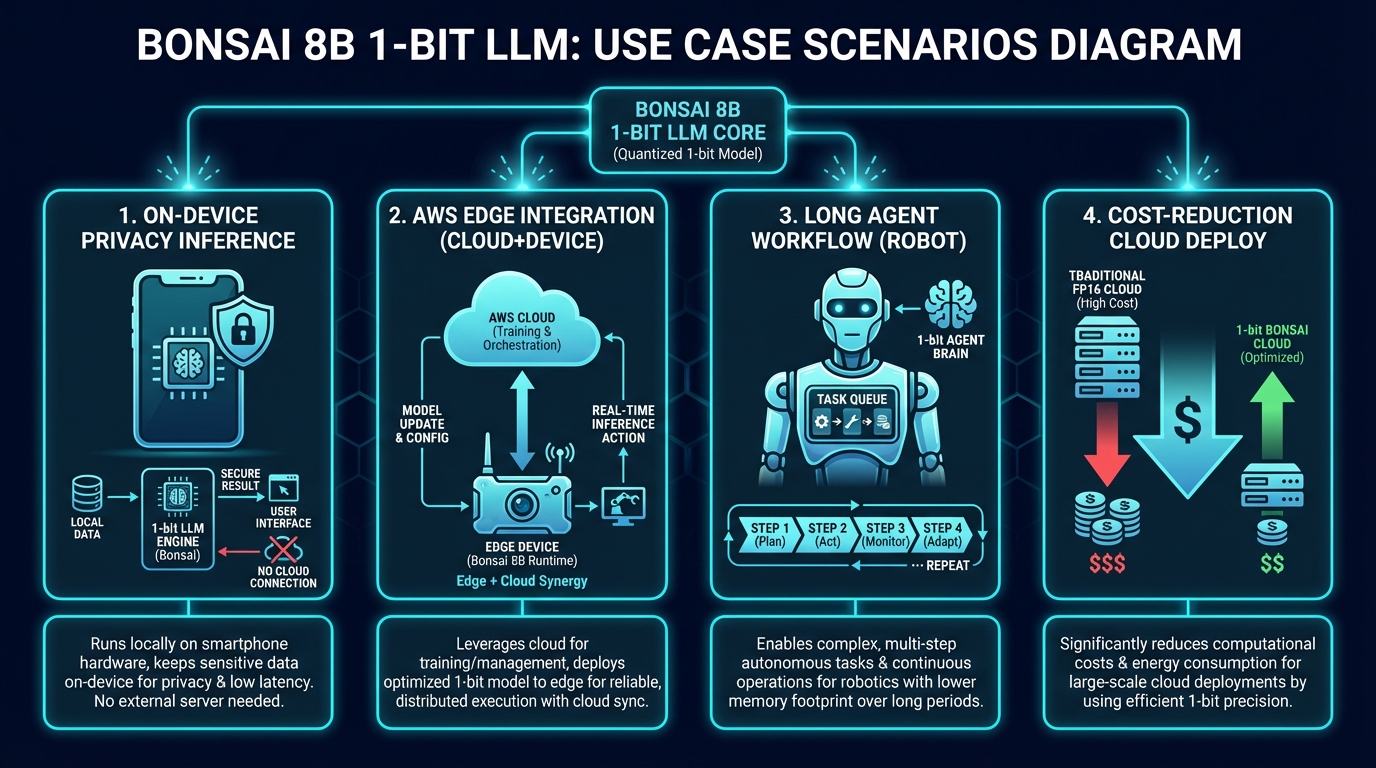
エンジニアが今すぐ試せる活用シナリオ
Bonsai 8BはApache 2.0ライセンスで公開されており、今すぐ商用プロジェクトへの適用が可能です。代表的な活用シナリオをエンジニア視点で紹介します。
オンデバイス・プライバシー重視の推論
機密データを含む会話AI、法律文書の要約、医療記録の処理など、クラウドに送信できないデータを扱うユースケースに最適です。Apple Siliconネイティブの MLX形式を使えば、Macやi Padで即座に動作させられます。データが外部サーバーに送出されないため、データレジデンシー要件の厳しいエンタープライズ環境でも安心して利用できます。
AWSエッジ環境への組み込み
GGUF形式(llama.cpp対応)を活用すれば、AWS IoT GreengrassでエッジデバイスにBonsai 8Bを展開できます。工場の異常検知、物流センターのリアルタイム判断、農業用ドローンの作物診断など、クラウド接続が不安定な環境でも8B級の推論能力を維持できます。
また、RTX 4090相当のNVIDIA GPUを搭載したEC2インスタンス(p3・g5系)であれば、秒間368トークンの高スループット処理が可能です。同じGPUメモリ容量で複数のBonsaiインスタンスを並行稼働させることで、スループットをさらに向上させられます。
長時間エージェントワークフロー
マルチステップのエージェント処理、例えばコードレビューの自動化、大量ドキュメントのバッチ処理、継続的なモニタリングエージェントなどで真価を発揮します。従来の16ビットモデルでは同一時間内に6件の処理しかできなかったタスクを、Bonsai 8Bなら50件こなせるというデモ結果は、実業務への適用インパクトを端的に示しています。
コスト削減のクラウドデプロイ
クラウドAPIのコストを抑えたい場合も有力な選択肢です。1.15GBのモデルサイズにより、従来は16GB必要だったGPUメモリ枠に複数のモデルインスタンスを同居させることができ、GPU利用効率を大幅に改善できます。
導入前に知っておきたい注意点と現状の制限
Bonsai 8Bは非常に有望なモデルですが、エンジニアとして冷静に評価すべき点もあります。
まず、現時点でのベンチマーク結果はPrismML自身が公表したデータが中心です。BenchLMなどの独立した評価プラットフォームでは、2026年4月時点で126のベンチマーク中4つしか検証が完了していない状況です。「インテリジェンス密度」という指標もPrismML独自のフレーミングであり、業界標準の指標による第三者評価は現在進行中です。
次に、ネイティブ1ビットハードウェアはまだ存在しません。現在の速度向上は、主にモデルサイズ削減によるメモリ転送量の削減から来ており、1ビット演算を直接実行する専用ハードウェアが実現した場合には、さらなる大幅な性能向上が期待できます。
Instruction Followingのカテゴリでは、BenchLMの評価で104モデル中62位という結果も出ており、複雑な指示に対する追従性については他の最新モデルと慎重な比較評価が必要です。
また、モバイルでの電力測定はXcode Power Profilerによる推定値であり、ハードウェアレベルでの実測値とは異なる場合があります。実際のデプロイ環境で独自にベンチマークを取ることをお勧めします。
1ビットLLMがもたらすAI展開の未来
Bonsai 8Bが示すのは、単一モデルの性能向上だけでなく、AIの展開アーキテクチャそのものの変化です。
かつてAIはクラウドに集約されるものでした。しかし1.15GBのモデルが8B級の推論を可能にするなら、スマートフォン、ラップトップ、組み込みデバイス、産業用ロボットのすべてが高性能AIのエンドポイントになりえます。
PrismMLはこれを「クラウド、エッジ、その間のすべてにAIが広がる未来」と表現しています。注目すべきは、エッジAIの普及がクラウドインフラへの需要を減らすのではなく、むしろ増やすという逆説です。より多くのエッジデバイスがAIを使えば、モデルの更新、ファインチューニング、複雑な推論のエスカレーション、データ同期のためにバックエンドのクラウドインフラへの需要が増大します。
エンジニアの視点では、このトレンドはアーキテクチャ設計の選択肢を大幅に広げるものです。「軽量タスクはエッジのBonsaiで、複雑な推論はAWS Bedrockで」というハイブリッド構成が、コストとレイテンシの最適解として現実的な選択肢になりつつあります。
PrismMLのCEO Babak Hassibiが「数年かけて開発した数学的理論」と述べる1ビット量子化技術は、1ビット専用ハードウェアが実現した暁にはさらなるパラダイムシフトをもたらすでしょう。Bonsai 8Bは、その未来への確かな第一歩です。
Apache 2.0ライセンスで公開されているため、今すぐHugging Faceからモデルをダウンロードして試すことができます。エッジAIの新しい可能性を、ぜひ実際に体験してみてください。
























