



マイクロソフトは2026年4月9日、ローカルAI実行環境「Foundry Local」の一般提供(GA: General Availability)を正式に発表しました。これはアプリケーションにAI推論エンジンごとバンドルし、インストーラとして配布できるという、これまでにない形のローカルAIソリューションです。クラウドへの依存を排除しながら、Windows・macOS・LinuxというメジャープラットフォームすべてをカバーするFoundry Localは、エンジニアにとって見逃せない選択肢となっています。
本記事では、Foundry Localの概要・アーキテクチャ・マルチプラットフォーム対応・配布モデルを技術的な視点から解説するとともに、クラウドネイティブ移行を支援してきたRagate株式会社としての見解もお伝えします。
Foundry Localとは クラウド不要のローカルAI実行環境
Foundry Localは、「アプリケーションがユーザーのデバイス上で完全に動作するAI機能を持つ」ためのエンドツーエンドのローカルAIソリューションです。マイクロソフトが提供するこのツールの核心は、モデルの取得・ハードウェアアクセラレーション・推論処理のすべてをアプリ内で完結させるという点にあります。
従来のAIシステムはクラウドAPIへのリクエストが前提であり、ネットワークレイテンシ・トークンごとの課金・データの外部送信というトレードオフを抱えていました。Foundry Localはこれらの課題をデバイス上のローカル実行によって解決します。
- プライバシー保護 ― プロンプトや出力結果がデバイス外に出ることがありません
- オフライン動作 ― ネットワーク接続なしでAI機能を利用できます
- ゼロトークン課金 ― 推論コストが発生しないため、コスト予測が容易です
- 低レイテンシ ― ネットワーク往復がないためリアルタイム性の高い応答が実現できます
- Azureサブスクリプション不要 ― クラウドアカウントを持たないユーザー向けのアプリにも組み込めます
Foundry Localは「汎用モデル実験用ツール」ではなく、本番アプリケーションに組み込んで配布することを目的とした本番用ランタイムです。そのため、モデルカタログは精選されており、各モデルはコンシューマーグレードのハードウェアで動作することが検証されています。
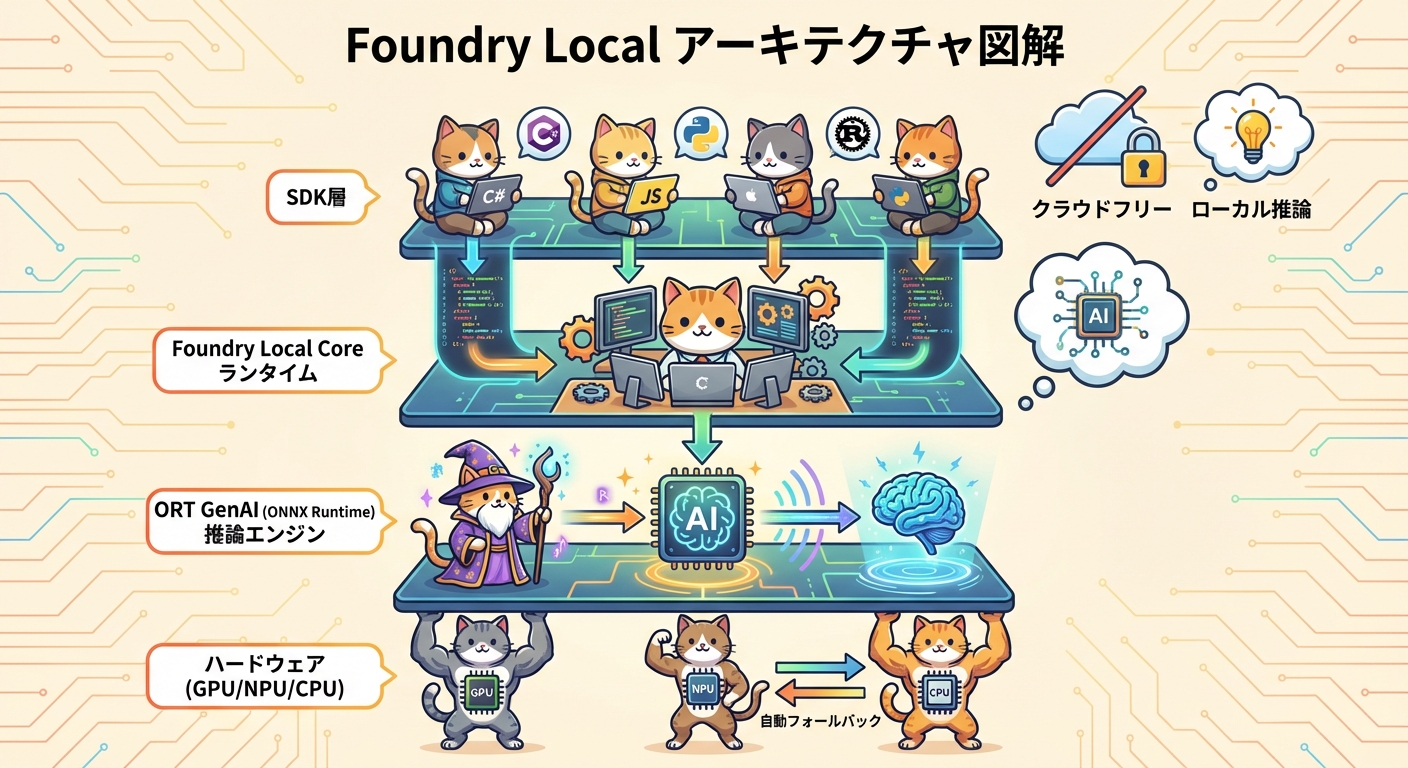
アーキテクチャの全体像 ORT GenAIが支えるクロスプラットフォーム推論
Foundry Localのアーキテクチャは、大きく3つの層で構成されています。
1. Foundry Local SDK(アプリ統合層)
開発者がアプリケーションから直接呼び出す薄いラッパー層です。C#・JavaScript・Python・Rustの4言語に対応しており、既存のOpenAI SDKを利用しているアプリケーションは、エンドポイントをFoundry Localに向けるだけで最小限のコード変更で移行できます。
2. Foundry Local Core(ネイティブランタイム)
モデルのダウンロード・キャッシュ管理・ライフサイクル全体を担うネイティブランタイムです。初回実行時にモデルを自動ダウンロードし、以降はローカルキャッシュから瞬時に起動します。ダウンロードが中断されても再開(レジューム)できる設計になっています。
3. ONNX Runtime / ORT GenAI(推論エンジン)
実際のモデル推論を担うエンジンがORT GenAI(ONNX Runtime GenAI)です。ONNX Runtime はマイクロソフトが開発するオープンソースの推論エンジンで、Foundry Localのほか、Windows ML、VS Code AI Toolkitでも共通して使用されています。量子化・圧縮済みモデルを効率的に実行し、GPU・NPU・CPUすべてのハードウェアに対して最適化された実行パスを提供します。
関連コンポーネントとして、Phi Silicaも注目に値します。Phi SilicaはWindowsに搭載されたAI API群のひとつで、NPU(ニューラルプロセッシングユニット)に最適化されたタスク実行を担います。Windows MLの一部として提供されており、Foundry LocalのWindowsプラットフォーム上でのハードウェア最適化を支える役割を果たしています。
ハードウェアアクセラレーションは完全自動です。Foundry Localはデバイスの利用可能なGPU・NPU・CPUを検出し、最も適した実行プロバイダーを自動的に選択します。開発者がハードウェア検出コードを書く必要はなく、ドライバーや実行プロバイダーの更新も自動で管理されます。
Windows・macOS・Linuxへの対応 各プラットフォームの最適化
Foundry Localが正式サポートするプラットフォームは以下の3つです。
Windows
Windows環境ではWindows MLとのネイティブ統合によりGPUおよびNPUのハードウェアアクセラレーションが有効になります。インストールはwingetで一行で完了します。
winget install Microsoft.FoundryLocalmacOS(Apple Silicon)
macOSではApple SiliconのGPUをMetal API経由でフル活用します。M1以降のチップを搭載したMacでは、GPUアクセラレーションにより高いスループットを実現します。インストールはHomebrewで行います。
brew install microsoft/foundrylocal/foundrylocalなお、現時点ではApple Silicon(Mシリーズ)のみが対応対象であり、Intel Macはサポートされていないためご注意ください。
Linux(x64)
Linux環境ではx64アーキテクチャに対応しており、GPU・CPUどちらの実行も可能です。Linuxサーバー上での開発・テスト用途にも活用できます。
アプリにバンドルして配布できる仕組み ゼロセットアップを実現
Foundry Localの最大の特徴のひとつが、アプリケーションのインストーラにAI実行環境ごと同梱して配布できる点です。
ランタイム本体のサイズは約20MBと軽量です。これはアプリのダウンロードサイズに与える影響を最小限に抑えながら、完全にセルフコンテインドなAI機能付きアプリを配布できることを意味しています。
ユーザーが追加で行う設定はゼロです。AIモデルの初回ダウンロードはアプリの起動時に自動で行われ、以降はローカルキャッシュから即座に利用できます。クラウドサービスのAPIキー設定やアカウント作成といった手順が不要なため、非技術系エンドユーザー向けのアプリにもAI機能を組み込みやすい設計になっています。
対応モデルカタログ
Foundry Localが提供するモデルカタログは、コンシューマーグレードのハードウェアでの動作が検証されたモデルに精選されています。
- Phi(Phi-4系を含むマイクロソフト製小型モデル群)
- Qwen(アリババ製の多言語対応モデル)
- DeepSeek(高性能な中国発OSSモデル)
- Mistral(欧州発のオープンソース高性能モデル)
- GPT OSS(OpenAIのオープンソース系モデル)
- Whisper(音声文字起こしに特化したOpenAIのモデル)
すべてのモデルは量子化・圧縮処理が施されており、ストレージ容量と推論速度のバランスが最適化されています。バージョンを固定して使用することも、自動更新を受け取ることも選択できます。
OpenAI互換APIの提供
Foundry LocalはOpenAI互換のREST APIを提供しています。チャット補完(Chat Completions)と音声文字起こし(Audio Transcription)はOpenAI形式のリクエスト・レスポンスをそのまま利用でき、OpenAI SDKを使用している既存のアプリケーションはエンドポイントの変更のみでローカル推論への移行が可能です。さらに、Open Responses API形式にも対応しており、クラウドとオンデバイスをシームレスに切り替えられる設計になっています。
Ragate視点 クラウドネイティブとローカルAIの新しい関係性
クラウドネイティブ移行の支援を多数手がけてきたRagate株式会社として、Foundry Localの登場は非常に興味深い動きだと捉えています。
私たちがこれまで支援してきた企業の多くは、AIシステムの導入においてクラウドAPIを前提とした設計を採用していました。Amazon BedrockやAzure OpenAI Serviceをはじめとするマネージドサービスは、インフラ管理の負担を減らしながらスケーラビリティを確保できるという点で、クラウドネイティブの文脈でも自然な選択です。
しかしFoundry Localのようなローカル実行環境の成熟は、クラウドとローカルの「二択」から「ハイブリッド戦略」への転換を後押ししています。特に以下のようなシナリオでは、ローカルAIが実質的な優位性を持ちます。
- 機密データを扱う業務アプリ ― 医療・法務・金融など、データを外部に出せない要件がある場合
- オフライン・エッジ環境 ― 工場内端末・フィールドワーク機器・航空機内など、常時接続が保証されない環境
- 高頻度のAI呼び出し ― トークン課金コストが積み重なるユースケースでのコスト最適化
- 低レイテンシが必要なリアルタイム処理 ― キーストロークへの即時応答など、クラウド往復では遅延が許容されない処理
また、Foundry LocalのOpenAI互換APIは、クラウドとローカルを同一コードベースで切り替えられるという点で、アーキテクチャ上の柔軟性を高めます。開発・テスト時はローカルで無料実行し、本番ではクラウドに切り替えるといった運用も可能です。
クラウドネイティブを推進してきた立場からも、「すべてをクラウドへ」ではなく「適材適所でクラウドとエッジを使い分ける」という設計思想が、AI時代のインフラ戦略においてますます重要になると感じています。Foundry Localはその実現を後押しするプロダクトのひとつとして、今後の動向を注視していきたいと思います。
マイクロソフトのFoundry Localはまだ進化の途中で、Azure Local統合やリアルタイム音声文字起こし、複数アプリ間でのモデルキャッシュ共有といった機能が今後のロードマップに挙げられています。ローカルAIの可能性をぜひご自身の開発プロジェクトで試してみてください。
























